Example evaluation of FOCUS Laboratory Data L1 to L3
Johannes Ranke
2016-12-08
Laboratory Data L1
The following code defines example dataset L1 from the FOCUS kinetics report, p. 284:
library("mkin", quietly = TRUE)
FOCUS_2006_L1 = data.frame(
t = rep(c(0, 1, 2, 3, 5, 7, 14, 21, 30), each = 2),
parent = c(88.3, 91.4, 85.6, 84.5, 78.9, 77.6,
72.0, 71.9, 50.3, 59.4, 47.0, 45.1,
27.7, 27.3, 10.0, 10.4, 2.9, 4.0))
FOCUS_2006_L1_mkin <- mkin_wide_to_long(FOCUS_2006_L1)Here we use the assumptions of simple first order (SFO), the case of declining rate constant over time (FOMC) and the case of two different phases of the kinetics (DFOP). For a more detailed discussion of the models, please see the FOCUS kinetics report.
Since mkin version 0.9-32 (July 2014), we can use shorthand notation like "SFO" for parent only degradation models. The following two lines fit the model and produce the summary report of the model fit. This covers the numerical analysis given in the FOCUS report.
m.L1.SFO <- mkinfit("SFO", FOCUS_2006_L1_mkin, quiet = TRUE)
summary(m.L1.SFO)## mkin version: 0.9.44.9000
## R version: 3.3.2
## Date of fit: Thu Dec 8 07:59:15 2016
## Date of summary: Thu Dec 8 07:59:15 2016
##
## Equations:
## d_parent/dt = - k_parent_sink * parent
##
## Model predictions using solution type analytical
##
## Fitted with method Port using 37 model solutions performed in 0.087 s
##
## Weighting: none
##
## Starting values for parameters to be optimised:
## value type
## parent_0 89.85 state
## k_parent_sink 0.10 deparm
##
## Starting values for the transformed parameters actually optimised:
## value lower upper
## parent_0 89.850000 -Inf Inf
## log_k_parent_sink -2.302585 -Inf Inf
##
## Fixed parameter values:
## None
##
## Optimised, transformed parameters with symmetric confidence intervals:
## Estimate Std. Error Lower Upper
## parent_0 92.470 1.36800 89.570 95.370
## log_k_parent_sink -2.347 0.04057 -2.433 -2.261
##
## Parameter correlation:
## parent_0 log_k_parent_sink
## parent_0 1.0000 0.6248
## log_k_parent_sink 0.6248 1.0000
##
## Residual standard error: 2.948 on 16 degrees of freedom
##
## Backtransformed parameters:
## Confidence intervals for internally transformed parameters are asymmetric.
## t-test (unrealistically) based on the assumption of normal distribution
## for estimators of untransformed parameters.
## Estimate t value Pr(>t) Lower Upper
## parent_0 92.47000 67.58 2.170e-21 89.57000 95.3700
## k_parent_sink 0.09561 24.65 1.867e-14 0.08773 0.1042
##
## Chi2 error levels in percent:
## err.min n.optim df
## All data 3.424 2 7
## parent 3.424 2 7
##
## Resulting formation fractions:
## ff
## parent_sink 1
##
## Estimated disappearance times:
## DT50 DT90
## parent 7.249 24.08
##
## Data:
## time variable observed predicted residual
## 0 parent 88.3 92.471 -4.1710
## 0 parent 91.4 92.471 -1.0710
## 1 parent 85.6 84.039 1.5610
## 1 parent 84.5 84.039 0.4610
## 2 parent 78.9 76.376 2.5241
## 2 parent 77.6 76.376 1.2241
## 3 parent 72.0 69.412 2.5884
## 3 parent 71.9 69.412 2.4884
## 5 parent 50.3 57.330 -7.0301
## 5 parent 59.4 57.330 2.0699
## 7 parent 47.0 47.352 -0.3515
## 7 parent 45.1 47.352 -2.2515
## 14 parent 27.7 24.247 3.4528
## 14 parent 27.3 24.247 3.0528
## 21 parent 10.0 12.416 -2.4163
## 21 parent 10.4 12.416 -2.0163
## 30 parent 2.9 5.251 -2.3513
## 30 parent 4.0 5.251 -1.2513A plot of the fit is obtained with the plot function for mkinfit objects.
plot(m.L1.SFO, show_errmin = TRUE, main = "FOCUS L1 - SFO")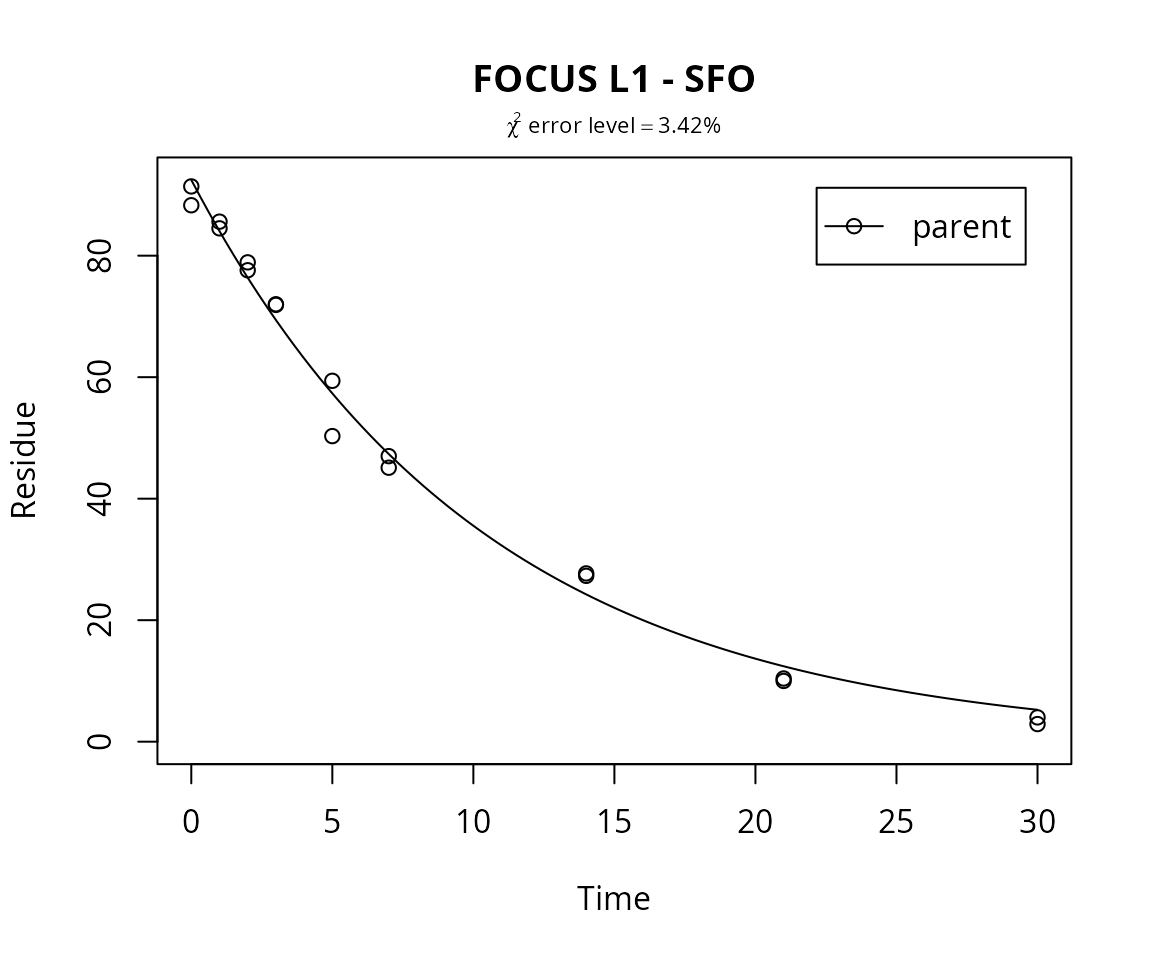
The residual plot can be easily obtained by
mkinresplot(m.L1.SFO, ylab = "Observed", xlab = "Time")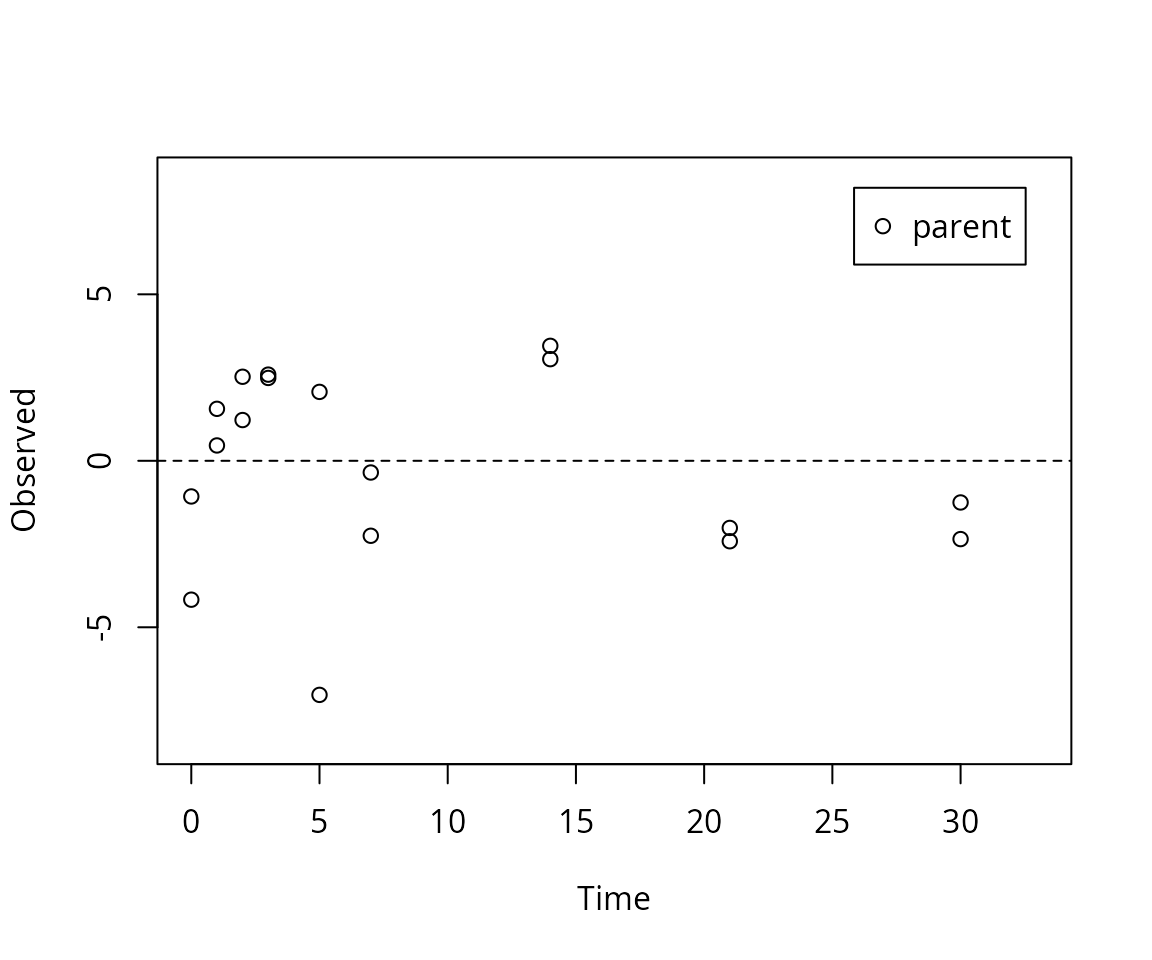
For comparison, the FOMC model is fitted as well, and the \(\chi^2\) error level is checked.
m.L1.FOMC <- mkinfit("FOMC", FOCUS_2006_L1_mkin, quiet=TRUE)## Warning in mkinfit("FOMC", FOCUS_2006_L1_mkin, quiet = TRUE): Optimisation by method Port did not converge.
## Convergence code is 1plot(m.L1.FOMC, show_errmin = TRUE, main = "FOCUS L1 - FOMC")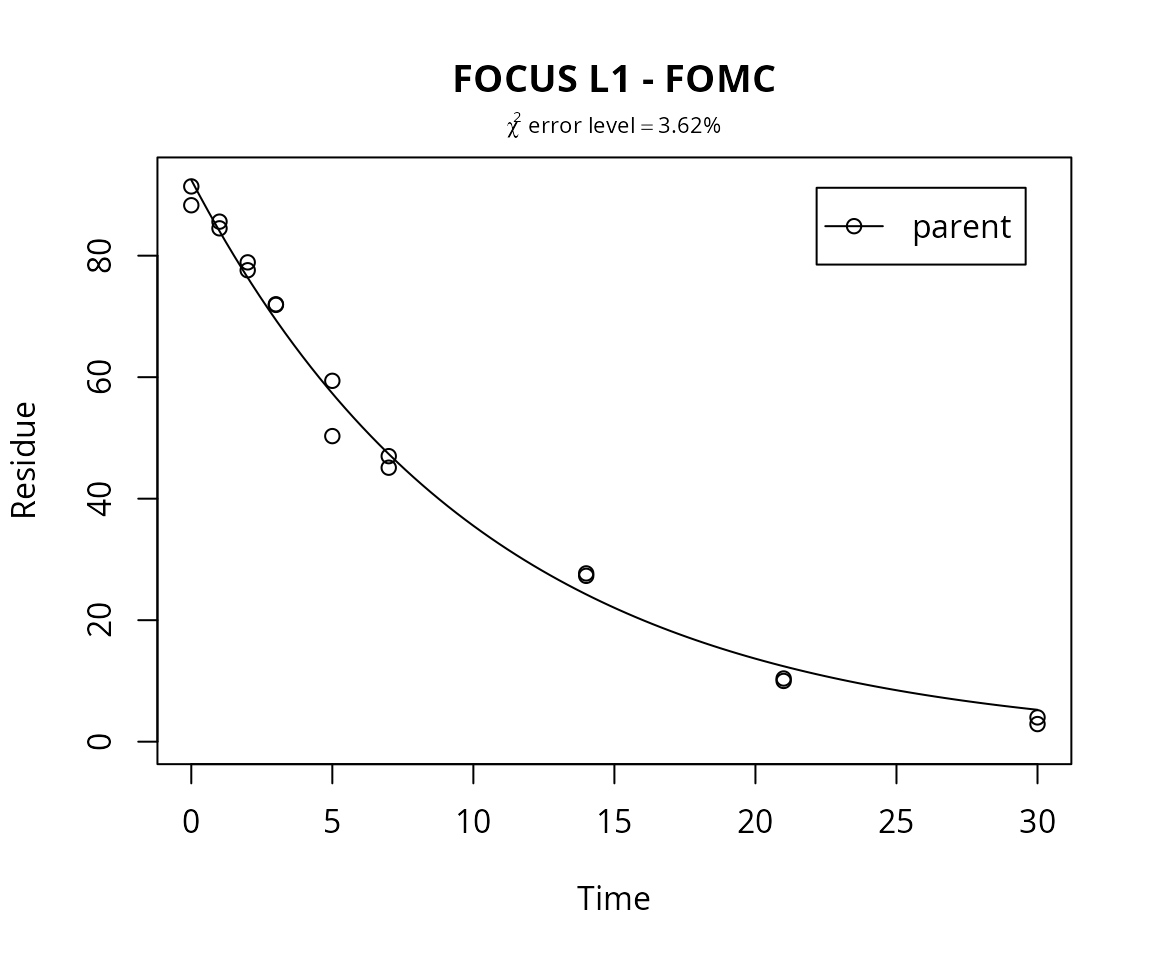
summary(m.L1.FOMC, data = FALSE)## mkin version: 0.9.44.9000
## R version: 3.3.2
## Date of fit: Thu Dec 8 07:59:15 2016
## Date of summary: Thu Dec 8 07:59:15 2016
##
##
## Warning: Optimisation by method Port did not converge.
## Convergence code is 1
##
##
## Equations:
## d_parent/dt = - (alpha/beta) * 1/((time/beta) + 1) * parent
##
## Model predictions using solution type analytical
##
## Fitted with method Port using 188 model solutions performed in 0.436 s
##
## Weighting: none
##
## Starting values for parameters to be optimised:
## value type
## parent_0 89.85 state
## alpha 1.00 deparm
## beta 10.00 deparm
##
## Starting values for the transformed parameters actually optimised:
## value lower upper
## parent_0 89.850000 -Inf Inf
## log_alpha 0.000000 -Inf Inf
## log_beta 2.302585 -Inf Inf
##
## Fixed parameter values:
## None
##
## Optimised, transformed parameters with symmetric confidence intervals:
## Estimate Std. Error Lower Upper
## parent_0 92.47 1.422 89.44 95.50
## log_alpha 15.43 15.080 -16.71 47.58
## log_beta 17.78 15.090 -14.37 49.93
##
## Parameter correlation:
## parent_0 log_alpha log_beta
## parent_0 1.0000 0.1129 0.1112
## log_alpha 0.1129 1.0000 1.0000
## log_beta 0.1112 1.0000 1.0000
##
## Residual standard error: 3.045 on 15 degrees of freedom
##
## Backtransformed parameters:
## Confidence intervals for internally transformed parameters are asymmetric.
## t-test (unrealistically) based on the assumption of normal distribution
## for estimators of untransformed parameters.
## Estimate t value Pr(>t) Lower Upper
## parent_0 9.247e+01 65.150 4.044e-20 8.944e+01 9.550e+01
## alpha 5.044e+06 1.271 1.115e-01 5.510e-08 4.618e+20
## beta 5.276e+07 1.259 1.137e-01 5.732e-07 4.857e+21
##
## Chi2 error levels in percent:
## err.min n.optim df
## All data 3.619 3 6
## parent 3.619 3 6
##
## Estimated disappearance times:
## DT50 DT90 DT50back
## parent 7.25 24.08 7.25We get a warning that the default optimisation algorithm Port did not converge, which is an indication that the model is overparameterised, i.e. contains too many parameters that are ill-defined as a consequence.
And in fact, due to the higher number of parameters, and the lower number of degrees of freedom of the fit, the \(\chi^2\) error level is actually higher for the FOMC model (3.6%) than for the SFO model (3.4%). Additionally, the parameters log_alpha and log_beta internally fitted in the model have excessive confidence intervals, that span more than 25 orders of magnitude (!) when backtransformed to the scale of alpha and beta. Also, the t-test for significant difference from zero does not indicate such a significant difference, with p-values greater than 0.1, and finally, the parameter correlation of log_alpha and log_beta is 1.000, clearly indicating that the model is overparameterised.
The \(\chi^2\) error levels reported in Appendix 3 and Appendix 7 to the FOCUS kinetics report are rounded to integer percentages and partly deviate by one percentage point from the results calculated by mkin. The reason for this is not known. However, mkin gives the same \(\chi^2\) error levels as the kinfit package and the calculation routines of the kinfit package have been extensively compared to the results obtained by the KinGUI software, as documented in the kinfit package vignette. KinGUI was the first widely used standard package in this field. Also, the calculation of \(\chi^2\) error levels was compared with KinGUII, CAKE and DegKin manager in a project sponsored by the German Umweltbundesamt (Ranke 2014).
Laboratory Data L2
The following code defines example dataset L2 from the FOCUS kinetics report, p. 287:
FOCUS_2006_L2 = data.frame(
t = rep(c(0, 1, 3, 7, 14, 28), each = 2),
parent = c(96.1, 91.8, 41.4, 38.7,
19.3, 22.3, 4.6, 4.6,
2.6, 1.2, 0.3, 0.6))
FOCUS_2006_L2_mkin <- mkin_wide_to_long(FOCUS_2006_L2)SFO fit for L2
Again, the SFO model is fitted and the result is plotted. The residual plot can be obtained simply by adding the argument show_residuals to the plot command.
m.L2.SFO <- mkinfit("SFO", FOCUS_2006_L2_mkin, quiet=TRUE)
plot(m.L2.SFO, show_residuals = TRUE, show_errmin = TRUE,
main = "FOCUS L2 - SFO")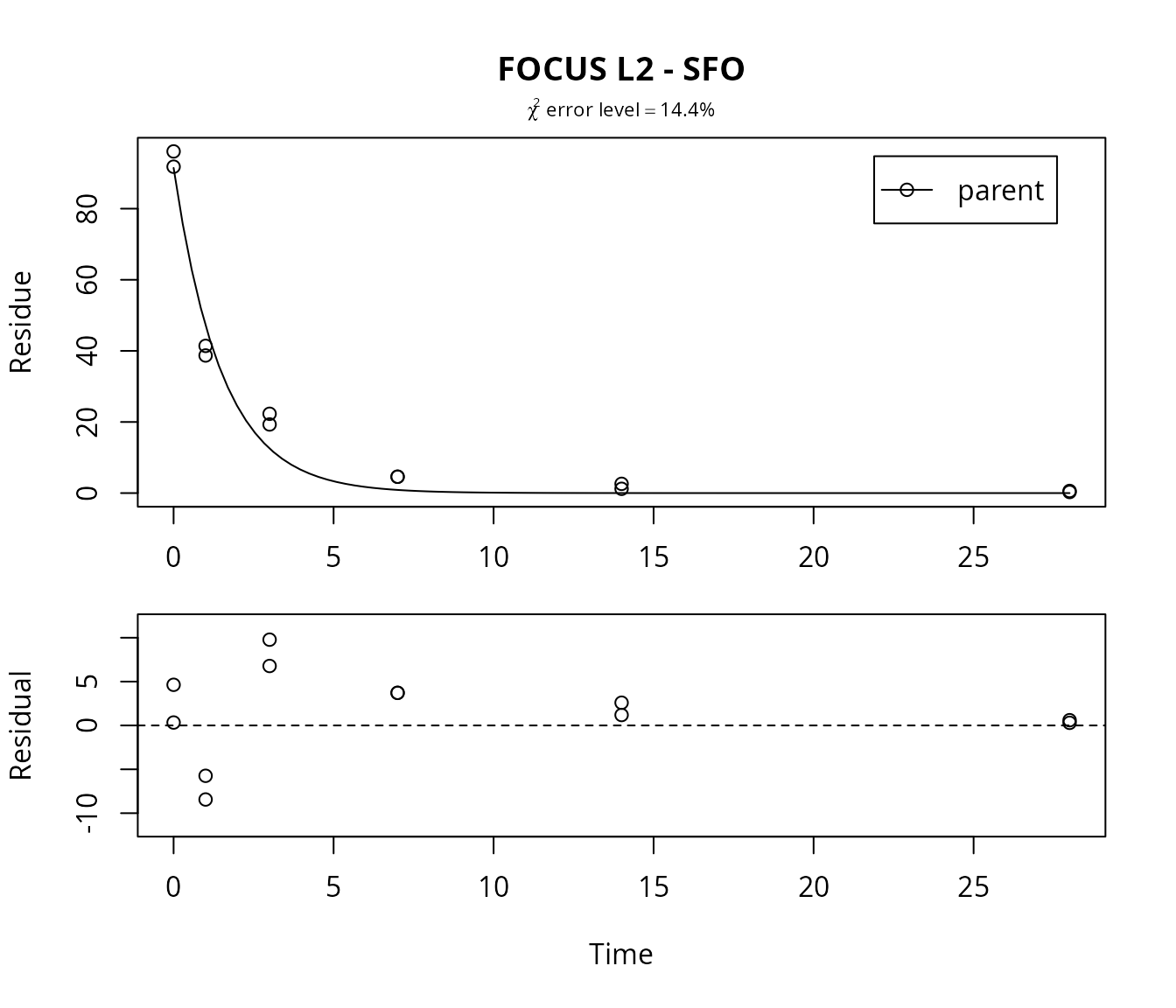
The \(\chi^2\) error level of 14% suggests that the model does not fit very well. This is also obvious from the plots of the fit, in which we have included the residual plot.
In the FOCUS kinetics report, it is stated that there is no apparent systematic error observed from the residual plot up to the measured DT90 (approximately at day 5), and there is an underestimation beyond that point.
We may add that it is difficult to judge the random nature of the residuals just from the three samplings at days 0, 1 and 3. Also, it is not clear a priori why a consistent underestimation after the approximate DT90 should be irrelevant. However, this can be rationalised by the fact that the FOCUS fate models generally only implement SFO kinetics.
FOMC fit for L2
For comparison, the FOMC model is fitted as well, and the \(\chi^2\) error level is checked.
m.L2.FOMC <- mkinfit("FOMC", FOCUS_2006_L2_mkin, quiet = TRUE)
plot(m.L2.FOMC, show_residuals = TRUE,
main = "FOCUS L2 - FOMC")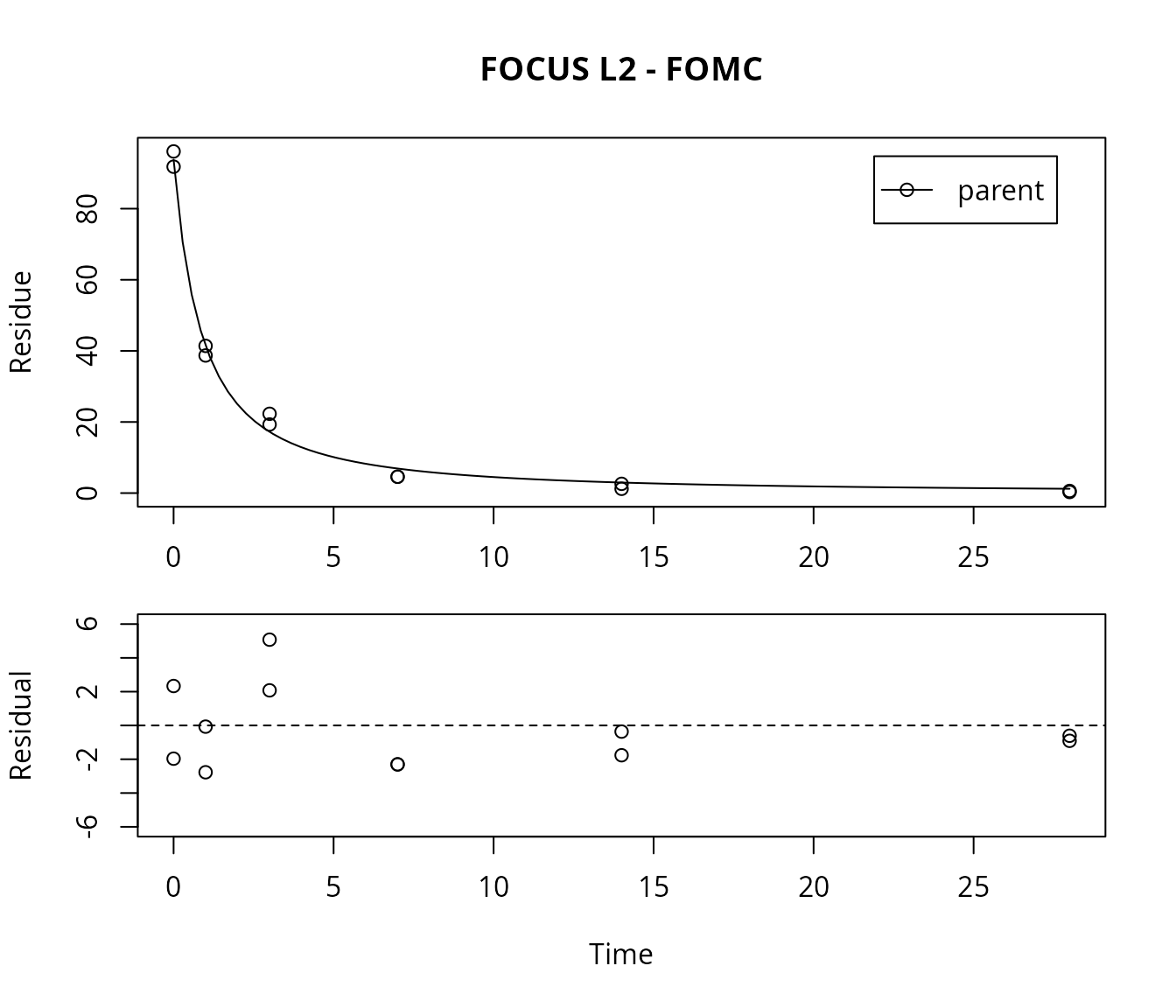
summary(m.L2.FOMC, data = FALSE)## mkin version: 0.9.44.9000
## R version: 3.3.2
## Date of fit: Thu Dec 8 07:59:16 2016
## Date of summary: Thu Dec 8 07:59:16 2016
##
## Equations:
## d_parent/dt = - (alpha/beta) * 1/((time/beta) + 1) * parent
##
## Model predictions using solution type analytical
##
## Fitted with method Port using 81 model solutions performed in 0.19 s
##
## Weighting: none
##
## Starting values for parameters to be optimised:
## value type
## parent_0 93.95 state
## alpha 1.00 deparm
## beta 10.00 deparm
##
## Starting values for the transformed parameters actually optimised:
## value lower upper
## parent_0 93.950000 -Inf Inf
## log_alpha 0.000000 -Inf Inf
## log_beta 2.302585 -Inf Inf
##
## Fixed parameter values:
## None
##
## Optimised, transformed parameters with symmetric confidence intervals:
## Estimate Std. Error Lower Upper
## parent_0 93.7700 1.8560 89.5700 97.9700
## log_alpha 0.3180 0.1867 -0.1044 0.7405
## log_beta 0.2102 0.2943 -0.4555 0.8759
##
## Parameter correlation:
## parent_0 log_alpha log_beta
## parent_0 1.00000 -0.09553 -0.1863
## log_alpha -0.09553 1.00000 0.9757
## log_beta -0.18628 0.97567 1.0000
##
## Residual standard error: 2.628 on 9 degrees of freedom
##
## Backtransformed parameters:
## Confidence intervals for internally transformed parameters are asymmetric.
## t-test (unrealistically) based on the assumption of normal distribution
## for estimators of untransformed parameters.
## Estimate t value Pr(>t) Lower Upper
## parent_0 93.770 50.510 1.173e-12 89.5700 97.970
## alpha 1.374 5.355 2.296e-04 0.9009 2.097
## beta 1.234 3.398 3.949e-03 0.6341 2.401
##
## Chi2 error levels in percent:
## err.min n.optim df
## All data 6.205 3 3
## parent 6.205 3 3
##
## Estimated disappearance times:
## DT50 DT90 DT50back
## parent 0.8092 5.356 1.612The error level at which the \(\chi^2\) test passes is much lower in this case. Therefore, the FOMC model provides a better description of the data, as less experimental error has to be assumed in order to explain the data.
DFOP fit for L2
Fitting the four parameter DFOP model further reduces the \(\chi^2\) error level.
m.L2.DFOP <- mkinfit("DFOP", FOCUS_2006_L2_mkin, quiet = TRUE)
plot(m.L2.DFOP, show_residuals = TRUE, show_errmin = TRUE,
main = "FOCUS L2 - DFOP")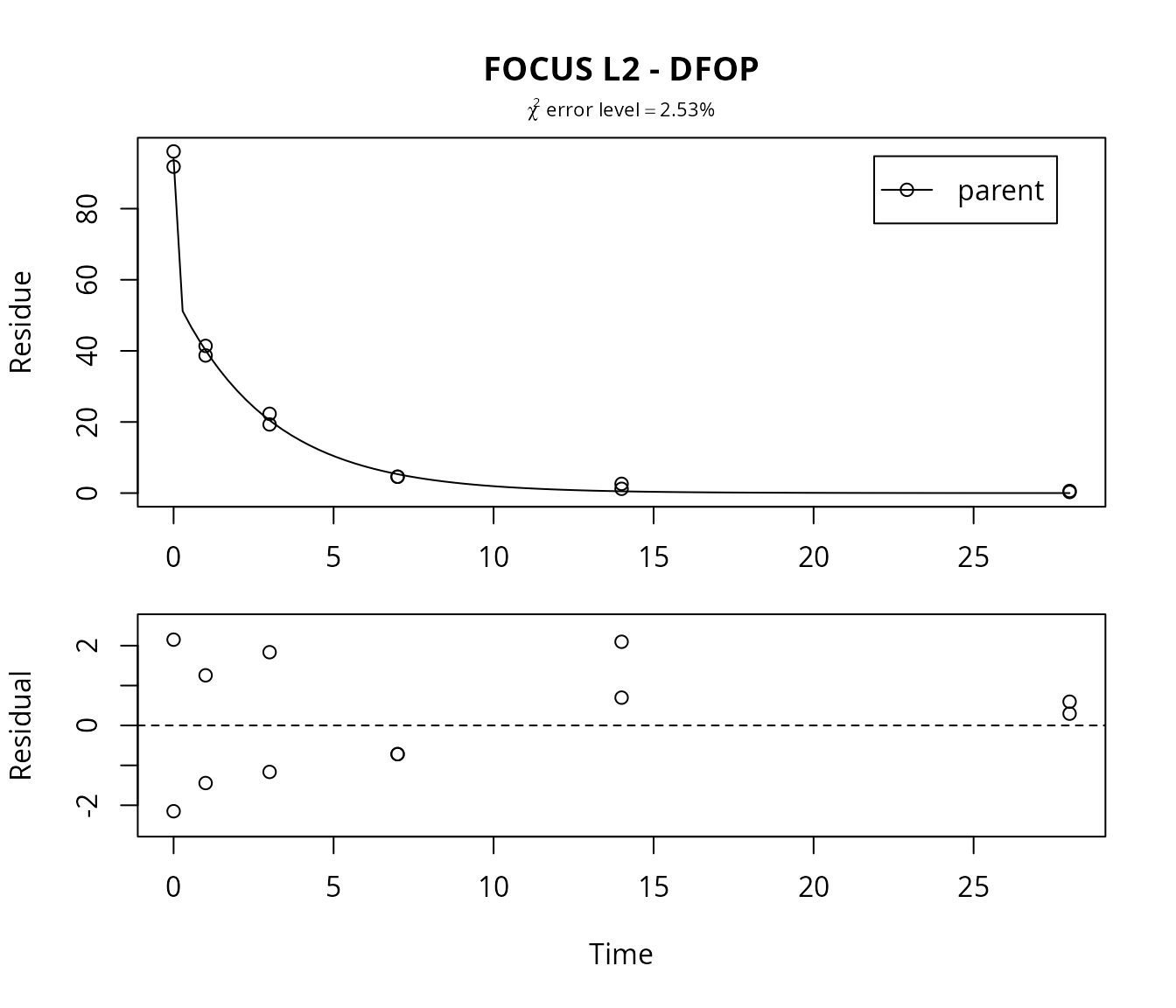
summary(m.L2.DFOP, data = FALSE)## mkin version: 0.9.44.9000
## R version: 3.3.2
## Date of fit: Thu Dec 8 07:59:17 2016
## Date of summary: Thu Dec 8 07:59:17 2016
##
## Equations:
## d_parent/dt = - ((k1 * g * exp(-k1 * time) + k2 * (1 - g) *
## exp(-k2 * time)) / (g * exp(-k1 * time) + (1 - g) *
## exp(-k2 * time))) * parent
##
## Model predictions using solution type analytical
##
## Fitted with method Port using 336 model solutions performed in 0.785 s
##
## Weighting: none
##
## Starting values for parameters to be optimised:
## value type
## parent_0 93.95 state
## k1 0.10 deparm
## k2 0.01 deparm
## g 0.50 deparm
##
## Starting values for the transformed parameters actually optimised:
## value lower upper
## parent_0 93.950000 -Inf Inf
## log_k1 -2.302585 -Inf Inf
## log_k2 -4.605170 -Inf Inf
## g_ilr 0.000000 -Inf Inf
##
## Fixed parameter values:
## None
##
## Optimised, transformed parameters with symmetric confidence intervals:
## Estimate Std. Error Lower Upper
## parent_0 93.9500 NA NA NA
## log_k1 3.1370 NA NA NA
## log_k2 -1.0880 NA NA NA
## g_ilr -0.2821 NA NA NA
##
## Parameter correlation:## Warning in print.summary.mkinfit(x): Could not estimate covariance matrix; singular system:## Could not estimate covariance matrix; singular system:
##
## Residual standard error: 1.732 on 8 degrees of freedom
##
## Backtransformed parameters:
## Confidence intervals for internally transformed parameters are asymmetric.
## t-test (unrealistically) based on the assumption of normal distribution
## for estimators of untransformed parameters.
## Estimate t value Pr(>t) Lower Upper
## parent_0 93.9500 NA NA NA NA
## k1 23.0400 NA NA NA NA
## k2 0.3369 NA NA NA NA
## g 0.4016 NA NA NA NA
##
## Chi2 error levels in percent:
## err.min n.optim df
## All data 2.53 4 2
## parent 2.53 4 2
##
## Estimated disappearance times:
## DT50 DT90 DT50_k1 DT50_k2
## parent 0.5335 5.311 0.03009 2.058Here, the DFOP model is clearly the best-fit model for dataset L2 based on the chi^2 error level criterion. However, the failure to calculate the covariance matrix indicates that the parameter estimates correlate excessively. Therefore, the FOMC model may be preferred for this dataset.
Laboratory Data L3
The following code defines example dataset L3 from the FOCUS kinetics report, p. 290.
FOCUS_2006_L3 = data.frame(
t = c(0, 3, 7, 14, 30, 60, 91, 120),
parent = c(97.8, 60, 51, 43, 35, 22, 15, 12))
FOCUS_2006_L3_mkin <- mkin_wide_to_long(FOCUS_2006_L3)Fit multiple models
As of mkin version 0.9-39 (June 2015), we can fit several models to one or more datasets in one call to the function mmkin. The datasets have to be passed in a list, in this case a named list holding only the L3 dataset prepared above.
# Only use one core here, not to offend the CRAN checks
mm.L3 <- mmkin(c("SFO", "FOMC", "DFOP"), cores = 1,
list("FOCUS L3" = FOCUS_2006_L3_mkin), quiet = TRUE)
plot(mm.L3)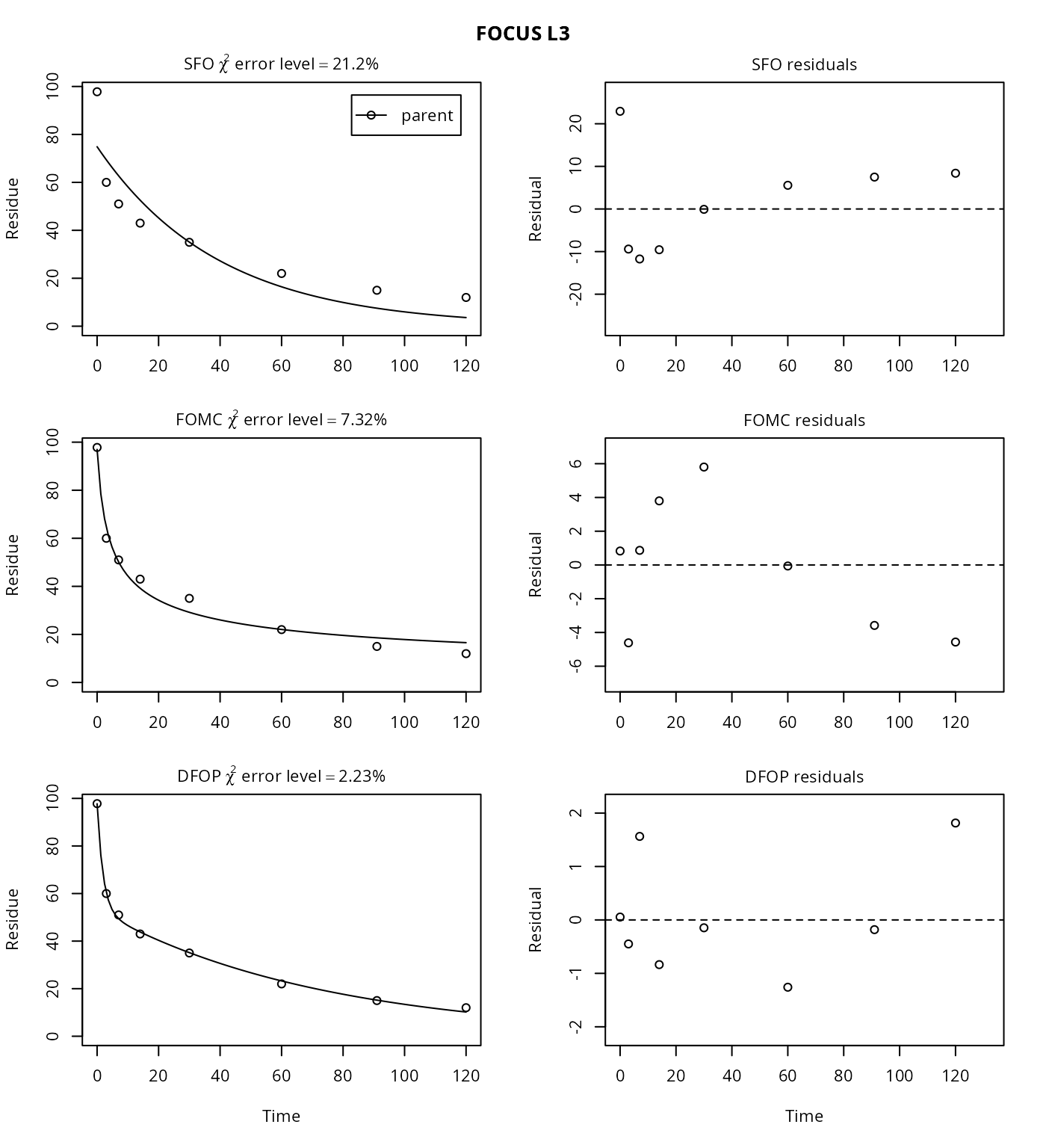
The \(\chi^2\) error level of 21% as well as the plot suggest that the SFO model does not fit very well. The FOMC model performs better, with an error level at which the \(\chi^2\) test passes of 7%. Fitting the four parameter DFOP model further reduces the \(\chi^2\) error level considerably.
Accessing mmkin objects
The objects returned by mmkin are arranged like a matrix, with models as a row index and datasets as a column index.
We can extract the summary and plot for e.g. the DFOP fit, using square brackets for indexing which will result in the use of the summary and plot functions working on mkinfit objects.
summary(mm.L3[["DFOP", 1]])## mkin version: 0.9.44.9000
## R version: 3.3.2
## Date of fit: Thu Dec 8 07:59:18 2016
## Date of summary: Thu Dec 8 07:59:18 2016
##
## Equations:
## d_parent/dt = - ((k1 * g * exp(-k1 * time) + k2 * (1 - g) *
## exp(-k2 * time)) / (g * exp(-k1 * time) + (1 - g) *
## exp(-k2 * time))) * parent
##
## Model predictions using solution type analytical
##
## Fitted with method Port using 137 model solutions performed in 0.319 s
##
## Weighting: none
##
## Starting values for parameters to be optimised:
## value type
## parent_0 97.80 state
## k1 0.10 deparm
## k2 0.01 deparm
## g 0.50 deparm
##
## Starting values for the transformed parameters actually optimised:
## value lower upper
## parent_0 97.800000 -Inf Inf
## log_k1 -2.302585 -Inf Inf
## log_k2 -4.605170 -Inf Inf
## g_ilr 0.000000 -Inf Inf
##
## Fixed parameter values:
## None
##
## Optimised, transformed parameters with symmetric confidence intervals:
## Estimate Std. Error Lower Upper
## parent_0 97.7500 1.43800 93.7500 101.70000
## log_k1 -0.6612 0.13340 -1.0310 -0.29100
## log_k2 -4.2860 0.05902 -4.4500 -4.12200
## g_ilr -0.1229 0.05121 -0.2651 0.01925
##
## Parameter correlation:
## parent_0 log_k1 log_k2 g_ilr
## parent_0 1.00000 0.1640 0.01315 0.4253
## log_k1 0.16400 1.0000 0.46478 -0.5526
## log_k2 0.01315 0.4648 1.00000 -0.6631
## g_ilr 0.42526 -0.5526 -0.66310 1.0000
##
## Residual standard error: 1.439 on 4 degrees of freedom
##
## Backtransformed parameters:
## Confidence intervals for internally transformed parameters are asymmetric.
## t-test (unrealistically) based on the assumption of normal distribution
## for estimators of untransformed parameters.
## Estimate t value Pr(>t) Lower Upper
## parent_0 97.75000 67.970 1.404e-07 93.75000 101.70000
## k1 0.51620 7.499 8.460e-04 0.35650 0.74750
## k2 0.01376 16.940 3.557e-05 0.01168 0.01621
## g 0.45660 25.410 7.121e-06 0.40730 0.50680
##
## Chi2 error levels in percent:
## err.min n.optim df
## All data 2.225 4 4
## parent 2.225 4 4
##
## Estimated disappearance times:
## DT50 DT90 DT50_k1 DT50_k2
## parent 7.464 123 1.343 50.37
##
## Data:
## time variable observed predicted residual
## 0 parent 97.8 97.75 0.05396
## 3 parent 60.0 60.45 -0.44933
## 7 parent 51.0 49.44 1.56338
## 14 parent 43.0 43.84 -0.83632
## 30 parent 35.0 35.15 -0.14707
## 60 parent 22.0 23.26 -1.25919
## 91 parent 15.0 15.18 -0.18181
## 120 parent 12.0 10.19 1.81395plot(mm.L3[["DFOP", 1]], show_errmin = TRUE)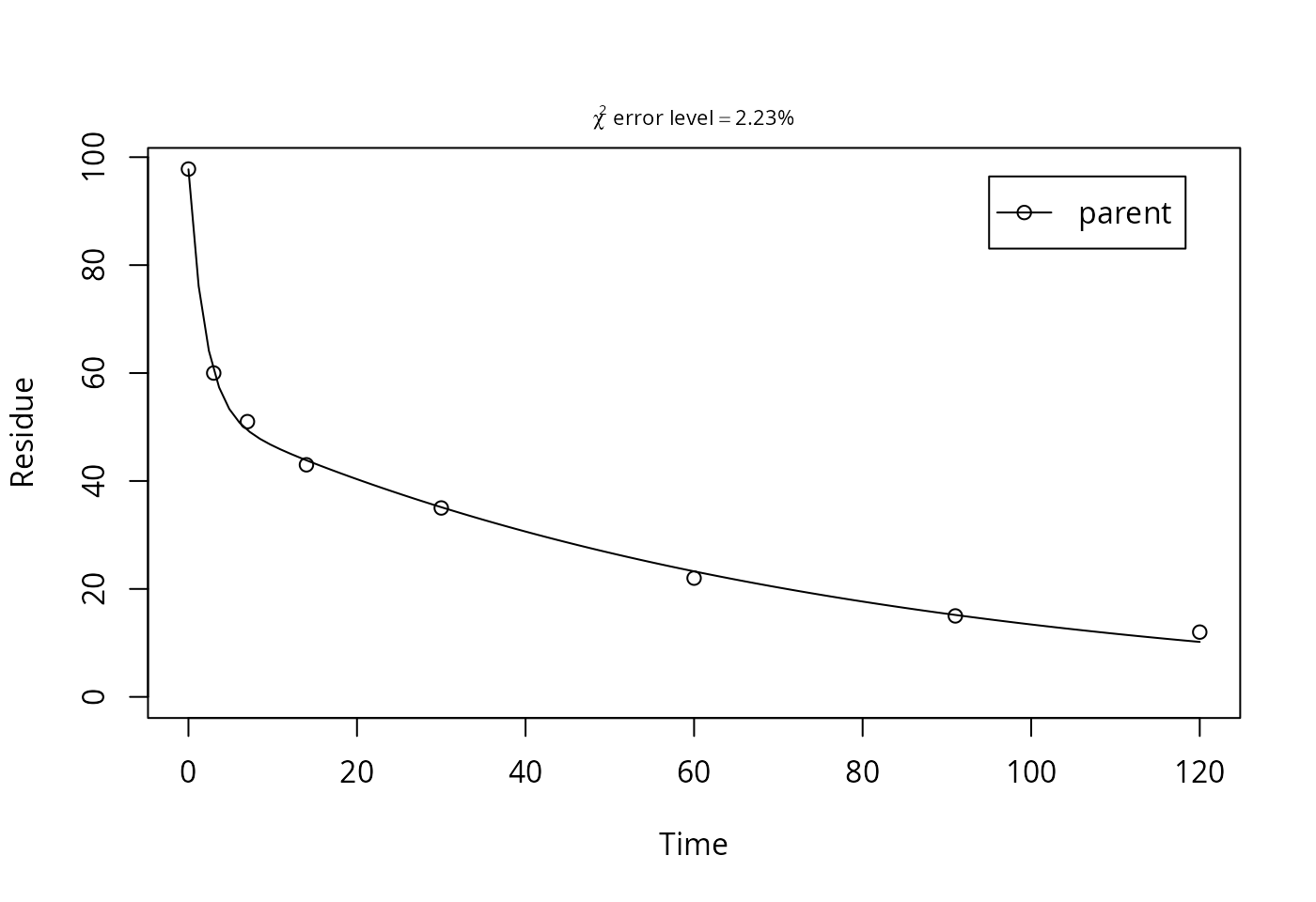
Here, a look to the model plot, the confidence intervals of the parameters and the correlation matrix suggest that the parameter estimates are reliable, and the DFOP model can be used as the best-fit model based on the \(\chi^2\) error level criterion for laboratory data L3.
This is also an example where the standard t-test for the parameter g_ilr is misleading, as it tests for a significant difference from zero. In this case, zero appears to be the correct value for this parameter, and the confidence interval for the backtransformed parameter g is quite narrow.
Laboratory Data L4
The following code defines example dataset L4 from the FOCUS kinetics report, p. 293:
FOCUS_2006_L4 = data.frame(
t = c(0, 3, 7, 14, 30, 60, 91, 120),
parent = c(96.6, 96.3, 94.3, 88.8, 74.9, 59.9, 53.5, 49.0))
FOCUS_2006_L4_mkin <- mkin_wide_to_long(FOCUS_2006_L4)Fits of the SFO and FOMC models, plots and summaries are produced below:
# Only use one core here, not to offend the CRAN checks
mm.L4 <- mmkin(c("SFO", "FOMC"), cores = 1,
list("FOCUS L4" = FOCUS_2006_L4_mkin),
quiet = TRUE)
plot(mm.L4)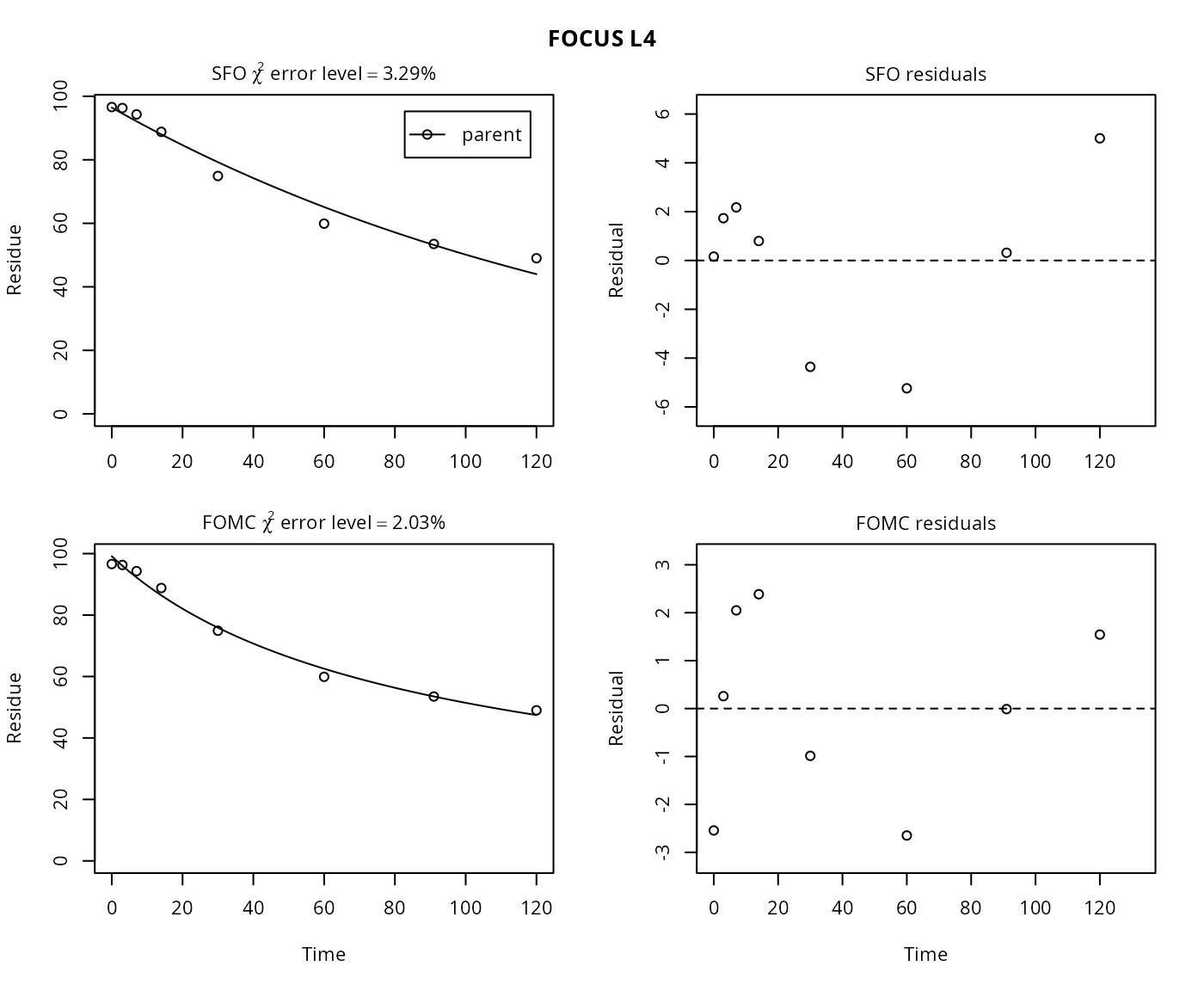
The \(\chi^2\) error level of 3.3% as well as the plot suggest that the SFO model fits very well. The error level at which the \(\chi^2\) test passes is slightly lower for the FOMC model. However, the difference appears negligible.
summary(mm.L4[["SFO", 1]], data = FALSE)## mkin version: 0.9.44.9000
## R version: 3.3.2
## Date of fit: Thu Dec 8 07:59:19 2016
## Date of summary: Thu Dec 8 07:59:19 2016
##
## Equations:
## d_parent/dt = - k_parent_sink * parent
##
## Model predictions using solution type analytical
##
## Fitted with method Port using 46 model solutions performed in 0.107 s
##
## Weighting: none
##
## Starting values for parameters to be optimised:
## value type
## parent_0 96.6 state
## k_parent_sink 0.1 deparm
##
## Starting values for the transformed parameters actually optimised:
## value lower upper
## parent_0 96.600000 -Inf Inf
## log_k_parent_sink -2.302585 -Inf Inf
##
## Fixed parameter values:
## None
##
## Optimised, transformed parameters with symmetric confidence intervals:
## Estimate Std. Error Lower Upper
## parent_0 96.44 1.94900 91.670 101.200
## log_k_parent_sink -5.03 0.07999 -5.225 -4.834
##
## Parameter correlation:
## parent_0 log_k_parent_sink
## parent_0 1.0000 0.5865
## log_k_parent_sink 0.5865 1.0000
##
## Residual standard error: 3.651 on 6 degrees of freedom
##
## Backtransformed parameters:
## Confidence intervals for internally transformed parameters are asymmetric.
## t-test (unrealistically) based on the assumption of normal distribution
## for estimators of untransformed parameters.
## Estimate t value Pr(>t) Lower Upper
## parent_0 96.440000 49.49 2.283e-09 91.670000 1.012e+02
## k_parent_sink 0.006541 12.50 8.008e-06 0.005378 7.955e-03
##
## Chi2 error levels in percent:
## err.min n.optim df
## All data 3.287 2 6
## parent 3.287 2 6
##
## Resulting formation fractions:
## ff
## parent_sink 1
##
## Estimated disappearance times:
## DT50 DT90
## parent 106 352summary(mm.L4[["FOMC", 1]], data = FALSE)## mkin version: 0.9.44.9000
## R version: 3.3.2
## Date of fit: Thu Dec 8 07:59:19 2016
## Date of summary: Thu Dec 8 07:59:19 2016
##
## Equations:
## d_parent/dt = - (alpha/beta) * 1/((time/beta) + 1) * parent
##
## Model predictions using solution type analytical
##
## Fitted with method Port using 66 model solutions performed in 0.152 s
##
## Weighting: none
##
## Starting values for parameters to be optimised:
## value type
## parent_0 96.6 state
## alpha 1.0 deparm
## beta 10.0 deparm
##
## Starting values for the transformed parameters actually optimised:
## value lower upper
## parent_0 96.600000 -Inf Inf
## log_alpha 0.000000 -Inf Inf
## log_beta 2.302585 -Inf Inf
##
## Fixed parameter values:
## None
##
## Optimised, transformed parameters with symmetric confidence intervals:
## Estimate Std. Error Lower Upper
## parent_0 99.1400 1.6800 94.820 103.5000
## log_alpha -0.3506 0.3725 -1.308 0.6068
## log_beta 4.1740 0.5635 2.726 5.6230
##
## Parameter correlation:
## parent_0 log_alpha log_beta
## parent_0 1.0000 -0.5365 -0.6083
## log_alpha -0.5365 1.0000 0.9913
## log_beta -0.6083 0.9913 1.0000
##
## Residual standard error: 2.315 on 5 degrees of freedom
##
## Backtransformed parameters:
## Confidence intervals for internally transformed parameters are asymmetric.
## t-test (unrealistically) based on the assumption of normal distribution
## for estimators of untransformed parameters.
## Estimate t value Pr(>t) Lower Upper
## parent_0 99.1400 59.020 1.322e-08 94.8200 103.500
## alpha 0.7042 2.685 2.178e-02 0.2703 1.835
## beta 64.9800 1.775 6.807e-02 15.2600 276.600
##
## Chi2 error levels in percent:
## err.min n.optim df
## All data 2.029 3 5
## parent 2.029 3 5
##
## Estimated disappearance times:
## DT50 DT90 DT50back
## parent 108.9 1644 494.9