Aerobic soil degradation data on dimethenamid and dimethenamid-P from the EU assessment in 2018
Source:R/dimethenamid_2018.R
dimethenamid_2018.RdThe datasets were extracted from the active substance evaluation dossier published by EFSA. Kinetic evaluations shown for these datasets are intended to illustrate and advance kinetic modelling. The fact that these data and some results are shown here does not imply a license to use them in the context of pesticide registrations, as the use of the data may be constrained by data protection regulations.
dimethenamid_2018Format
An mkindsg object grouping seven datasets with some meta information
Source
Rapporteur Member State Germany, Co-Rapporteur Member State Bulgaria (2018) Renewal Assessment Report Dimethenamid-P Volume 3 - B.8 Environmental fate and behaviour Rev. 2 - November 2017 https://open.efsa.europa.eu/study-inventory/EFSA-Q-2014-00716
Details
The R code used to create this data object is installed with this package in the 'dataset_generation' directory. In the code, page numbers are given for specific pieces of information in the comments.
Examples
print(dimethenamid_2018)
#> <mkindsg> holding 7 mkinds objects
#> Title $title: Aerobic soil degradation data on dimethenamid-P from the EU assessment in 2018
#> Occurrence of observed compounds $observed_n:
#> DMTAP M23 M27 M31 DMTA
#> 3 7 7 7 4
#> Time normalisation factors $f_time_norm:
#> [1] 1.0000000 0.9706477 1.2284784 1.2284784 0.6233856 0.7678922 0.6733938
#> Meta information $meta:
#> study usda_soil_type study_moisture_ref_type rel_moisture
#> Calke Unsworth 2014 Sandy loam pF2 1.00
#> Borstel Staudenmaier 2009 Sand pF1 0.50
#> Elliot 1 Wendt 1997 Clay loam pF2.5 0.75
#> Elliot 2 Wendt 1997 Clay loam pF2.5 0.75
#> Flaach König 1996 Sandy clay loam pF1 0.40
#> BBA 2.2 König 1995 Loamy sand pF1 0.40
#> BBA 2.3 König 1995 Sandy loam pF1 0.40
#> study_ref_moisture temperature
#> Calke NA 20
#> Borstel 23.00 20
#> Elliot 1 33.37 23
#> Elliot 2 33.37 23
#> Flaach NA 20
#> BBA 2.2 NA 20
#> BBA 2.3 NA 20
dmta_ds <- lapply(1:7, function(i) {
ds_i <- dimethenamid_2018$ds[[i]]$data
ds_i[ds_i$name == "DMTAP", "name"] <- "DMTA"
ds_i$time <- ds_i$time * dimethenamid_2018$f_time_norm[i]
ds_i
})
names(dmta_ds) <- sapply(dimethenamid_2018$ds, function(ds) ds$title)
dmta_ds[["Elliot"]] <- rbind(dmta_ds[["Elliot 1"]], dmta_ds[["Elliot 2"]])
dmta_ds[["Elliot 1"]] <- NULL
dmta_ds[["Elliot 2"]] <- NULL
# \dontrun{
# We don't use DFOP for the parent compound, as this gives numerical
# instabilities in the fits
sfo_sfo3p <- mkinmod(
DMTA = mkinsub("SFO", c("M23", "M27", "M31")),
M23 = mkinsub("SFO"),
M27 = mkinsub("SFO"),
M31 = mkinsub("SFO", "M27", sink = FALSE),
quiet = TRUE
)
dmta_sfo_sfo3p_tc <- mmkin(list("SFO-SFO3+" = sfo_sfo3p),
dmta_ds, error_model = "tc", quiet = TRUE)
print(dmta_sfo_sfo3p_tc)
#> <mmkin> object
#> Status of individual fits:
#>
#> dataset
#> model Calke Borstel Flaach BBA 2.2 BBA 2.3 Elliot
#> SFO-SFO3+ OK OK OK OK OK OK
#>
#> OK: No warnings
# The default (test_log_parms = FALSE) gives an undue
# influence of ill-defined rate constants that have
# extremely small values:
plot(mixed(dmta_sfo_sfo3p_tc), test_log_parms = FALSE)
# If we disregards ill-defined rate constants, the results
# look more plausible, but the truth is likely to be in
# between these variants
plot(mixed(dmta_sfo_sfo3p_tc), test_log_parms = TRUE)
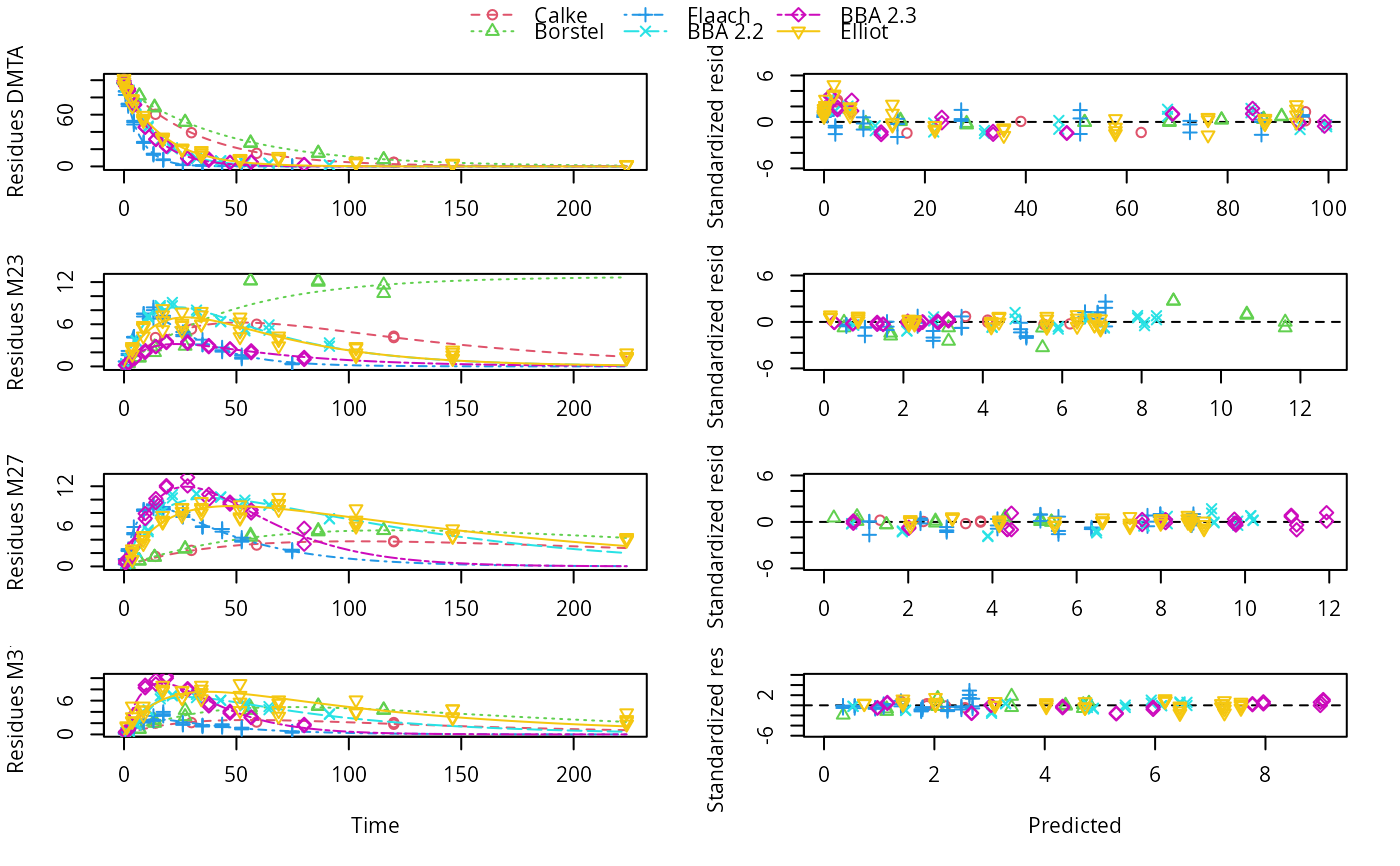 # We can also specify a default value for the failing
# log parameters, to mimic FOCUS guidance
plot(mixed(dmta_sfo_sfo3p_tc), test_log_parms = TRUE,
default_log_parms = log(2)/1000)
# As these attempts are not satisfying, we use nonlinear mixed-effects models
# f_dmta_nlme_tc <- nlme(dmta_sfo_sfo3p_tc)
# nlme reaches maxIter = 50 without convergence
f_dmta_saem_tc <- saem(dmta_sfo_sfo3p_tc)
# I am commenting out the convergence plot as rendering them
# with pkgdown fails (at least without further tweaks to the
# graphics device used)
#saemix::plot(f_dmta_saem_tc$so, plot.type = "convergence")
summary(f_dmta_saem_tc)
#> saemix version used for fitting: 3.2
#> mkin version used for pre-fitting: 1.2.2
#> R version used for fitting: 4.2.2
#> Date of fit: Thu Nov 24 08:05:16 2022
#> Date of summary: Thu Nov 24 08:05:16 2022
#>
#> Equations:
#> d_DMTA/dt = - k_DMTA * DMTA
#> d_M23/dt = + f_DMTA_to_M23 * k_DMTA * DMTA - k_M23 * M23
#> d_M27/dt = + f_DMTA_to_M27 * k_DMTA * DMTA - k_M27 * M27 + k_M31 * M31
#> d_M31/dt = + f_DMTA_to_M31 * k_DMTA * DMTA - k_M31 * M31
#>
#> Data:
#> 563 observations of 4 variable(s) grouped in 6 datasets
#>
#> Model predictions using solution type deSolve
#>
#> Fitted in 819.725 s
#> Using 300, 100 iterations and 9 chains
#>
#> Variance model: Two-component variance function
#>
#> Mean of starting values for individual parameters:
#> DMTA_0 log_k_DMTA log_k_M23 log_k_M27 log_k_M31 f_DMTA_ilr_1
#> 95.5662 -2.9048 -3.8130 -4.1600 -4.1486 0.1341
#> f_DMTA_ilr_2 f_DMTA_ilr_3
#> 0.1385 -1.6700
#>
#> Fixed degradation parameter values:
#> None
#>
#> Results:
#>
#> Likelihood computed by importance sampling
#> AIC BIC logLik
#> 2276 2273 -1120
#>
#> Optimised parameters:
#> est. lower upper
#> DMTA_0 88.3192 83.8656 92.7729
#> log_k_DMTA -3.0530 -3.5686 -2.5373
#> log_k_M23 -4.0620 -4.9202 -3.2038
#> log_k_M27 -3.8633 -4.2668 -3.4598
#> log_k_M31 -3.9731 -4.4763 -3.4699
#> f_DMTA_ilr_1 0.1346 -0.2150 0.4841
#> f_DMTA_ilr_2 0.1449 -0.2593 0.5491
#> f_DMTA_ilr_3 -1.3882 -1.7011 -1.0753
#> a.1 0.9156 0.8229 1.0084
#> b.1 0.1383 0.1215 0.1551
#> SD.DMTA_0 3.7280 -0.6951 8.1511
#> SD.log_k_DMTA 0.6431 0.2781 1.0080
#> SD.log_k_M23 1.0096 0.3782 1.6409
#> SD.log_k_M27 0.4583 0.1541 0.7625
#> SD.log_k_M31 0.5738 0.1942 0.9533
#> SD.f_DMTA_ilr_1 0.4119 0.1528 0.6709
#> SD.f_DMTA_ilr_2 0.4780 0.1806 0.7754
#> SD.f_DMTA_ilr_3 0.3657 0.1383 0.5931
#>
#> Correlation:
#> DMTA_0 l__DMTA lg__M23 lg__M27 lg__M31 f_DMTA__1 f_DMTA__2
#> log_k_DMTA 0.0303
#> log_k_M23 -0.0229 -0.0032
#> log_k_M27 -0.0372 -0.0049 0.0041
#> log_k_M31 -0.0245 -0.0032 0.0022 0.0815
#> f_DMTA_ilr_1 -0.0046 -0.0006 0.0415 -0.0433 0.0324
#> f_DMTA_ilr_2 -0.0008 -0.0002 0.0214 -0.0267 -0.0893 -0.0361
#> f_DMTA_ilr_3 -0.1755 -0.0135 0.0423 0.0775 0.0377 -0.0066 0.0060
#>
#> Random effects:
#> est. lower upper
#> SD.DMTA_0 3.7280 -0.6951 8.1511
#> SD.log_k_DMTA 0.6431 0.2781 1.0080
#> SD.log_k_M23 1.0096 0.3782 1.6409
#> SD.log_k_M27 0.4583 0.1541 0.7625
#> SD.log_k_M31 0.5738 0.1942 0.9533
#> SD.f_DMTA_ilr_1 0.4119 0.1528 0.6709
#> SD.f_DMTA_ilr_2 0.4780 0.1806 0.7754
#> SD.f_DMTA_ilr_3 0.3657 0.1383 0.5931
#>
#> Variance model:
#> est. lower upper
#> a.1 0.9156 0.8229 1.0084
#> b.1 0.1383 0.1215 0.1551
#>
#> Backtransformed parameters:
#> est. lower upper
#> DMTA_0 88.31924 83.865625 92.77286
#> k_DMTA 0.04722 0.028196 0.07908
#> k_M23 0.01721 0.007298 0.04061
#> k_M27 0.02100 0.014027 0.03144
#> k_M31 0.01882 0.011375 0.03112
#> f_DMTA_to_M23 0.14608 NA NA
#> f_DMTA_to_M27 0.12077 NA NA
#> f_DMTA_to_M31 0.11123 NA NA
#>
#> Resulting formation fractions:
#> ff
#> DMTA_M23 0.1461
#> DMTA_M27 0.1208
#> DMTA_M31 0.1112
#> DMTA_sink 0.6219
#>
#> Estimated disappearance times:
#> DT50 DT90
#> DMTA 14.68 48.76
#> M23 40.27 133.76
#> M27 33.01 109.65
#> M31 36.84 122.38
# As the confidence interval for the random effects of DMTA_0
# includes zero, we could try an alternative model without
# such random effects
# f_dmta_saem_tc_2 <- saem(dmta_sfo_sfo3p_tc,
# covariance.model = diag(c(0, rep(1, 7))))
# saemix::plot(f_dmta_saem_tc_2$so, plot.type = "convergence")
# This does not perform better judged by AIC and BIC
# saemix::compare.saemix(f_dmta_saem_tc$so, f_dmta_saem_tc_2$so)
# }
# We can also specify a default value for the failing
# log parameters, to mimic FOCUS guidance
plot(mixed(dmta_sfo_sfo3p_tc), test_log_parms = TRUE,
default_log_parms = log(2)/1000)
# As these attempts are not satisfying, we use nonlinear mixed-effects models
# f_dmta_nlme_tc <- nlme(dmta_sfo_sfo3p_tc)
# nlme reaches maxIter = 50 without convergence
f_dmta_saem_tc <- saem(dmta_sfo_sfo3p_tc)
# I am commenting out the convergence plot as rendering them
# with pkgdown fails (at least without further tweaks to the
# graphics device used)
#saemix::plot(f_dmta_saem_tc$so, plot.type = "convergence")
summary(f_dmta_saem_tc)
#> saemix version used for fitting: 3.2
#> mkin version used for pre-fitting: 1.2.2
#> R version used for fitting: 4.2.2
#> Date of fit: Thu Nov 24 08:05:16 2022
#> Date of summary: Thu Nov 24 08:05:16 2022
#>
#> Equations:
#> d_DMTA/dt = - k_DMTA * DMTA
#> d_M23/dt = + f_DMTA_to_M23 * k_DMTA * DMTA - k_M23 * M23
#> d_M27/dt = + f_DMTA_to_M27 * k_DMTA * DMTA - k_M27 * M27 + k_M31 * M31
#> d_M31/dt = + f_DMTA_to_M31 * k_DMTA * DMTA - k_M31 * M31
#>
#> Data:
#> 563 observations of 4 variable(s) grouped in 6 datasets
#>
#> Model predictions using solution type deSolve
#>
#> Fitted in 819.725 s
#> Using 300, 100 iterations and 9 chains
#>
#> Variance model: Two-component variance function
#>
#> Mean of starting values for individual parameters:
#> DMTA_0 log_k_DMTA log_k_M23 log_k_M27 log_k_M31 f_DMTA_ilr_1
#> 95.5662 -2.9048 -3.8130 -4.1600 -4.1486 0.1341
#> f_DMTA_ilr_2 f_DMTA_ilr_3
#> 0.1385 -1.6700
#>
#> Fixed degradation parameter values:
#> None
#>
#> Results:
#>
#> Likelihood computed by importance sampling
#> AIC BIC logLik
#> 2276 2273 -1120
#>
#> Optimised parameters:
#> est. lower upper
#> DMTA_0 88.3192 83.8656 92.7729
#> log_k_DMTA -3.0530 -3.5686 -2.5373
#> log_k_M23 -4.0620 -4.9202 -3.2038
#> log_k_M27 -3.8633 -4.2668 -3.4598
#> log_k_M31 -3.9731 -4.4763 -3.4699
#> f_DMTA_ilr_1 0.1346 -0.2150 0.4841
#> f_DMTA_ilr_2 0.1449 -0.2593 0.5491
#> f_DMTA_ilr_3 -1.3882 -1.7011 -1.0753
#> a.1 0.9156 0.8229 1.0084
#> b.1 0.1383 0.1215 0.1551
#> SD.DMTA_0 3.7280 -0.6951 8.1511
#> SD.log_k_DMTA 0.6431 0.2781 1.0080
#> SD.log_k_M23 1.0096 0.3782 1.6409
#> SD.log_k_M27 0.4583 0.1541 0.7625
#> SD.log_k_M31 0.5738 0.1942 0.9533
#> SD.f_DMTA_ilr_1 0.4119 0.1528 0.6709
#> SD.f_DMTA_ilr_2 0.4780 0.1806 0.7754
#> SD.f_DMTA_ilr_3 0.3657 0.1383 0.5931
#>
#> Correlation:
#> DMTA_0 l__DMTA lg__M23 lg__M27 lg__M31 f_DMTA__1 f_DMTA__2
#> log_k_DMTA 0.0303
#> log_k_M23 -0.0229 -0.0032
#> log_k_M27 -0.0372 -0.0049 0.0041
#> log_k_M31 -0.0245 -0.0032 0.0022 0.0815
#> f_DMTA_ilr_1 -0.0046 -0.0006 0.0415 -0.0433 0.0324
#> f_DMTA_ilr_2 -0.0008 -0.0002 0.0214 -0.0267 -0.0893 -0.0361
#> f_DMTA_ilr_3 -0.1755 -0.0135 0.0423 0.0775 0.0377 -0.0066 0.0060
#>
#> Random effects:
#> est. lower upper
#> SD.DMTA_0 3.7280 -0.6951 8.1511
#> SD.log_k_DMTA 0.6431 0.2781 1.0080
#> SD.log_k_M23 1.0096 0.3782 1.6409
#> SD.log_k_M27 0.4583 0.1541 0.7625
#> SD.log_k_M31 0.5738 0.1942 0.9533
#> SD.f_DMTA_ilr_1 0.4119 0.1528 0.6709
#> SD.f_DMTA_ilr_2 0.4780 0.1806 0.7754
#> SD.f_DMTA_ilr_3 0.3657 0.1383 0.5931
#>
#> Variance model:
#> est. lower upper
#> a.1 0.9156 0.8229 1.0084
#> b.1 0.1383 0.1215 0.1551
#>
#> Backtransformed parameters:
#> est. lower upper
#> DMTA_0 88.31924 83.865625 92.77286
#> k_DMTA 0.04722 0.028196 0.07908
#> k_M23 0.01721 0.007298 0.04061
#> k_M27 0.02100 0.014027 0.03144
#> k_M31 0.01882 0.011375 0.03112
#> f_DMTA_to_M23 0.14608 NA NA
#> f_DMTA_to_M27 0.12077 NA NA
#> f_DMTA_to_M31 0.11123 NA NA
#>
#> Resulting formation fractions:
#> ff
#> DMTA_M23 0.1461
#> DMTA_M27 0.1208
#> DMTA_M31 0.1112
#> DMTA_sink 0.6219
#>
#> Estimated disappearance times:
#> DT50 DT90
#> DMTA 14.68 48.76
#> M23 40.27 133.76
#> M27 33.01 109.65
#> M31 36.84 122.38
# As the confidence interval for the random effects of DMTA_0
# includes zero, we could try an alternative model without
# such random effects
# f_dmta_saem_tc_2 <- saem(dmta_sfo_sfo3p_tc,
# covariance.model = diag(c(0, rep(1, 7))))
# saemix::plot(f_dmta_saem_tc_2$so, plot.type = "convergence")
# This does not perform better judged by AIC and BIC
# saemix::compare.saemix(f_dmta_saem_tc$so, f_dmta_saem_tc_2$so)
# }