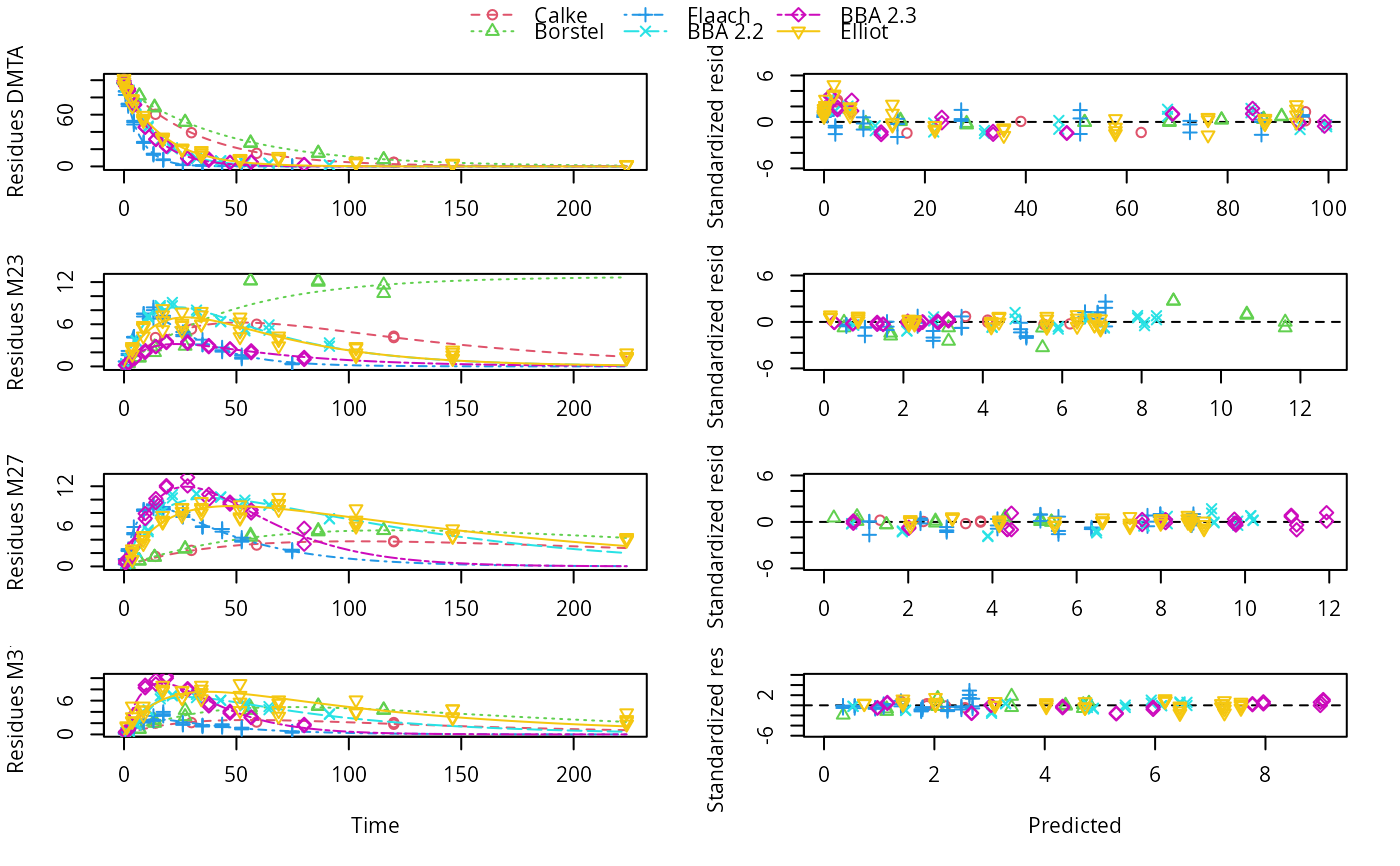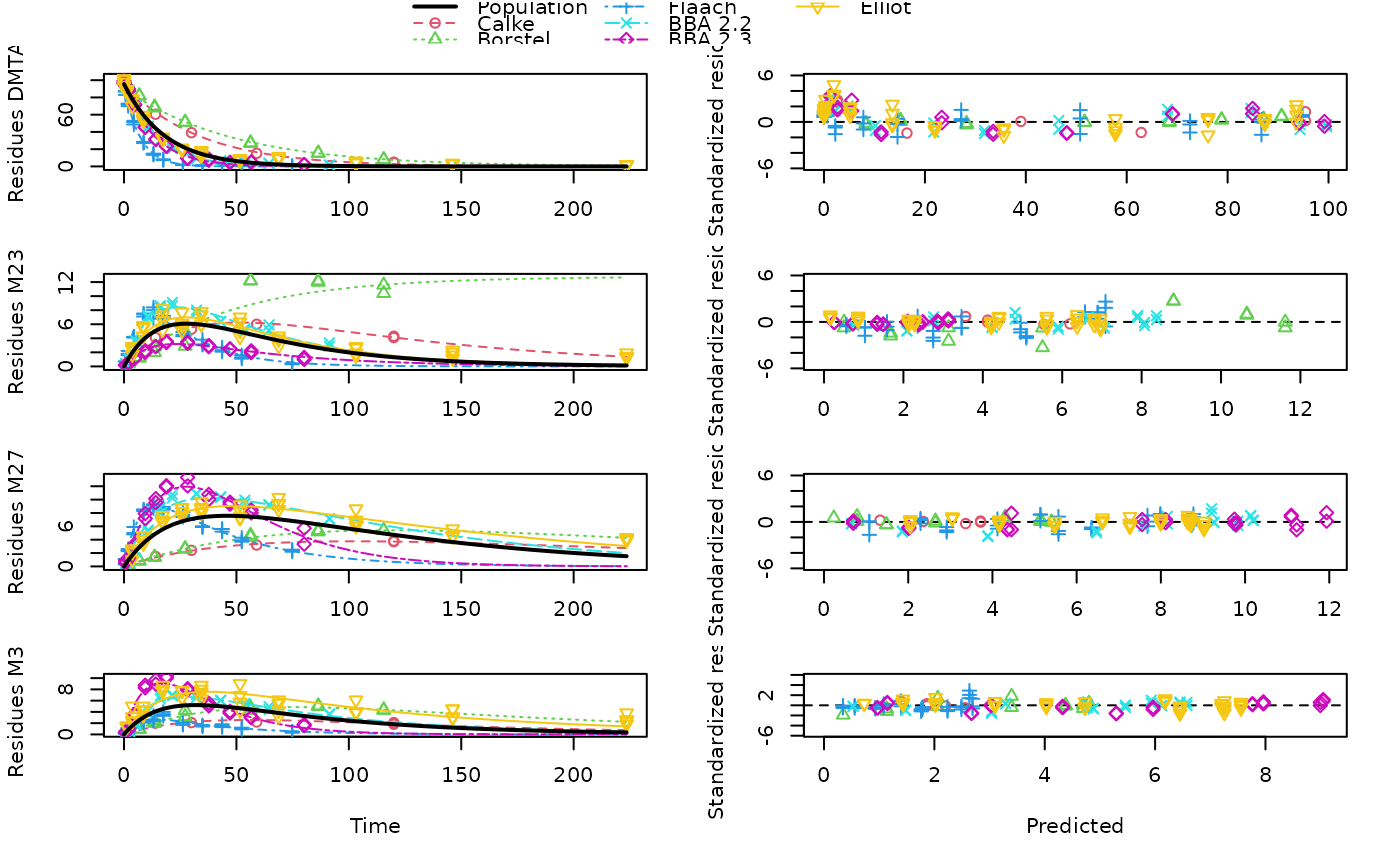Aerobic soil degradation data on dimethenamid and dimethenamid-P from the EU assessment in 2018
Source:R/dimethenamid_2018.R
dimethenamid_2018.RdThe datasets were extracted from the active substance evaluation dossier published by EFSA. Kinetic evaluations shown for these datasets are intended to illustrate and advance kinetic modelling. The fact that these data and some results are shown here does not imply a license to use them in the context of pesticide registrations, as the use of the data may be constrained by data protection regulations.
dimethenamid_2018
Format
An mkindsg object grouping eight datasets with some meta information
Source
Rapporteur Member State Germany, Co-Rapporteur Member State Bulgaria (2018) Renewal Assessment Report Dimethenamid-P Volume 3 - B.8 Environmental fate and behaviour Rev. 2 - November 2017 https://open.efsa.europa.eu/study-inventory/EFSA-Q-2014-00716
Details
The R code used to create this data object is installed with this package in the 'dataset_generation' directory. In the code, page numbers are given for specific pieces of information in the comments.
Examples
#> <mkindsg> holding 8 mkinds objects #> Title $title: Aerobic soil degradation data on dimethenamid-P from the EU assessment in 2018 #> Occurrence of observed compounds $observed_n: #> DMTAP M23 M27 M31 DMTA #> 4 7 7 7 4 #> Time normalisation factors $f_time_norm: #> [1] 1.0000000 0.9706477 0.9706477 1.2284784 1.2284784 0.6233856 0.7678922 #> [8] 0.6733938 #> Meta information $meta: #> study usda_soil_type study_moisture_ref_type #> Calke Unsworth 2014 Sandy loam pF2 #> Borstel 1 Staudenmaier 2013 Sand pF1 #> Borstel 2 Staudenmaier 2009 Sand pF1 #> Elliot 1 Wendt 1997 Clay loam pF2.5 #> Elliot 2 Wendt 1997 Clay loam pF2.5 #> Flaach König 1996 Sandy clay loam pF1 #> BBA 2.2 König 1995 Loamy sand pF1 #> BBA 2.3 König 1995 Sandy loam pF1 #> rel_moisture study_ref_moisture temperature #> Calke 1.00 NA 20 #> Borstel 1 0.50 23.00 20 #> Borstel 2 0.50 23.00 20 #> Elliot 1 0.75 33.37 23 #> Elliot 2 0.75 33.37 23 #> Flaach 0.40 NA 20 #> BBA 2.2 0.40 NA 20 #> BBA 2.3 0.40 NA 20dmta_ds <- lapply(1:8, function(i) { ds_i <- dimethenamid_2018$ds[[i]]$data ds_i[ds_i$name == "DMTAP", "name"] <- "DMTA" ds_i$time <- ds_i$time * dimethenamid_2018$f_time_norm[i] ds_i }) names(dmta_ds) <- sapply(dimethenamid_2018$ds, function(ds) ds$title) dmta_ds[["Borstel"]] <- rbind(dmta_ds[["Borstel 1"]], dmta_ds[["Borstel 2"]]) dmta_ds[["Borstel 1"]] <- NULL dmta_ds[["Borstel 2"]] <- NULL dmta_ds[["Elliot"]] <- rbind(dmta_ds[["Elliot 1"]], dmta_ds[["Elliot 2"]]) dmta_ds[["Elliot 1"]] <- NULL dmta_ds[["Elliot 2"]] <- NULL # \dontrun{ dfop_sfo3_plus <- mkinmod( DMTA = mkinsub("DFOP", c("M23", "M27", "M31")), M23 = mkinsub("SFO"), M27 = mkinsub("SFO"), M31 = mkinsub("SFO", "M27", sink = FALSE), quiet = TRUE ) f_dmta_mkin_tc <- mmkin( list("DFOP-SFO3+" = dfop_sfo3_plus), dmta_ds, quiet = TRUE, error_model = "tc") nlmixr_model(f_dmta_mkin_tc)#>#> function () #> { #> ini({ #> DMTA_0 = 98.7697627680706 #> eta.DMTA_0 ~ 2.35171765917765 #> log_k_M23 = -3.92162409637283 #> eta.log_k_M23 ~ 0.549278519419884 #> log_k_M27 = -4.33774620773911 #> eta.log_k_M27 ~ 0.864474956685295 #> log_k_M31 = -4.24767627688461 #> eta.log_k_M31 ~ 0.750297149164171 #> log_k1 = -2.2341008812259 #> eta.log_k1 ~ 0.902976221565793 #> log_k2 = -3.7762779983269 #> eta.log_k2 ~ 1.57684519529298 #> g_qlogis = 0.450175725479389 #> eta.g_qlogis ~ 3.0851335687675 #> f_DMTA_tffm0_1_qlogis = -2.09240906629456 #> eta.f_DMTA_tffm0_1_qlogis ~ 0.3 #> f_DMTA_tffm0_2_qlogis = -2.18057573598794 #> eta.f_DMTA_tffm0_2_qlogis ~ 0.3 #> f_DMTA_tffm0_3_qlogis = -2.14267187609763 #> eta.f_DMTA_tffm0_3_qlogis ~ 0.3 #> sigma_low_DMTA = 0.697933852349996 #> rsd_high_DMTA = 0.0257724286053519 #> sigma_low_M23 = 0.697933852349996 #> rsd_high_M23 = 0.0257724286053519 #> sigma_low_M27 = 0.697933852349996 #> rsd_high_M27 = 0.0257724286053519 #> sigma_low_M31 = 0.697933852349996 #> rsd_high_M31 = 0.0257724286053519 #> }) #> model({ #> DMTA_0_model = DMTA_0 + eta.DMTA_0 #> DMTA(0) = DMTA_0_model #> k_M23 = exp(log_k_M23 + eta.log_k_M23) #> k_M27 = exp(log_k_M27 + eta.log_k_M27) #> k_M31 = exp(log_k_M31 + eta.log_k_M31) #> k1 = exp(log_k1 + eta.log_k1) #> k2 = exp(log_k2 + eta.log_k2) #> g = expit(g_qlogis + eta.g_qlogis) #> f_DMTA_tffm0_1 = expit(f_DMTA_tffm0_1_qlogis + eta.f_DMTA_tffm0_1_qlogis) #> f_DMTA_tffm0_2 = expit(f_DMTA_tffm0_2_qlogis + eta.f_DMTA_tffm0_2_qlogis) #> f_DMTA_tffm0_3 = expit(f_DMTA_tffm0_3_qlogis + eta.f_DMTA_tffm0_3_qlogis) #> f_DMTA_to_M23 = f_DMTA_tffm0_1 #> f_DMTA_to_M27 = f_DMTA_tffm0_2 * (1 - f_DMTA_tffm0_1) #> f_DMTA_to_M31 = f_DMTA_tffm0_3 * (1 - f_DMTA_tffm0_2) * #> (1 - f_DMTA_tffm0_1) #> d/dt(DMTA) = -((k1 * g * exp(-k1 * time) + k2 * (1 - #> g) * exp(-k2 * time))/(g * exp(-k1 * time) + (1 - #> g) * exp(-k2 * time))) * DMTA #> d/dt(M23) = +f_DMTA_to_M23 * ((k1 * g * exp(-k1 * time) + #> k2 * (1 - g) * exp(-k2 * time))/(g * exp(-k1 * time) + #> (1 - g) * exp(-k2 * time))) * DMTA - k_M23 * M23 #> d/dt(M27) = +f_DMTA_to_M27 * ((k1 * g * exp(-k1 * time) + #> k2 * (1 - g) * exp(-k2 * time))/(g * exp(-k1 * time) + #> (1 - g) * exp(-k2 * time))) * DMTA - k_M27 * M27 + #> k_M31 * M31 #> d/dt(M31) = +f_DMTA_to_M31 * ((k1 * g * exp(-k1 * time) + #> k2 * (1 - g) * exp(-k2 * time))/(g * exp(-k1 * time) + #> (1 - g) * exp(-k2 * time))) * DMTA - k_M31 * M31 #> DMTA ~ add(sigma_low_DMTA) + prop(rsd_high_DMTA) #> M23 ~ add(sigma_low_M23) + prop(rsd_high_M23) #> M27 ~ add(sigma_low_M27) + prop(rsd_high_M27) #> M31 ~ add(sigma_low_M31) + prop(rsd_high_M31) #> }) #> } #> <environment: 0x555559c00ce8># The focei fit takes about four minutes on my system system.time( f_dmta_nlmixr_focei <- nlmixr(f_dmta_mkin_tc, est = "focei", control = nlmixr::foceiControl(print = 500)) )#>#>#>#>#>#>#>#>#>#>#>#>#>#> [====|====|====|====|====|====|====|====|====|====] 0:00:02 #>#>#> [====|====|====|====|====|====|====|====|====|====] 0:00:04 #>#>#> [====|====|====|====|====|====|====|====|====|====] 0:00:01 #>#>#> [====|====|====|====|====|====|====|====|====|====] 0:00:08 #>#>#> [====|====|====|====|====|====|====|====|====|====] 0:00:07 #>#>#> [====|====|====|====|====|====|====|====|====|====] 0:00:07 #>#>#> [====|====|====|====|====|====|====|====|====|====] 0:00:00 #>#>#> [====|====|====|====|====|====|====|====|====|====] 0:00:00 #>#>#>#>#>#>#>#>#>#>#>#>#>#>#>#> [1] "CMT"#> #>#> Key: U: Unscaled Parameters; X: Back-transformed parameters; G: Gill difference gradient approximation #> F: Forward difference gradient approximation #> C: Central difference gradient approximation #> M: Mixed forward and central difference gradient approximation #> Unscaled parameters for Omegas=chol(solve(omega)); #> Diagonals are transformed, as specified by foceiControl(diagXform=) #> |-----+---------------+-----------+-----------+-----------+-----------| #> | #| Objective Fun | DMTA_0 | log_k_M23 | log_k_M27 | log_k_M31 | #> |.....................| log_k1 | log_k2 | g_qlogis |f_DMTA_tffm0_1_qlogis | #> |.....................|f_DMTA_tffm0_2_qlogis |f_DMTA_tffm0_3_qlogis | sigma_low | rsd_high | #> |.....................| o1 | o2 | o3 | o4 | #> |.....................| o5 | o6 | o7 | o8 | #> |.....................| o9 | o10 |...........|...........| #> calculating covariance matrix #> done#>#>#> Warning: initial ETAs were nudged; (can control by foceiControl(etaNudge=., etaNudge2=))#> Warning: last objective function was not at minimum, possible problems in optimization#> Warning: S matrix non-positive definite#> Warning: using R matrix to calculate covariance#> Warning: gradient problems with initial estimate and covariance; see $scaleInfo#> user system elapsed #> 227.879 9.742 237.728#> nlmixr version used for fitting: 2.0.4 #> mkin version used for pre-fitting: 1.1.0 #> R version used for fitting: 4.1.0 #> Date of fit: Tue Jul 27 16:02:33 2021 #> Date of summary: Tue Jul 27 16:02:34 2021 #> #> Equations: #> d_DMTA/dt = - ((k1 * g * exp(-k1 * time) + k2 * (1 - g) * exp(-k2 * #> time)) / (g * exp(-k1 * time) + (1 - g) * exp(-k2 * time))) #> * DMTA #> d_M23/dt = + f_DMTA_to_M23 * ((k1 * g * exp(-k1 * time) + k2 * (1 - g) #> * exp(-k2 * time)) / (g * exp(-k1 * time) + (1 - g) * #> exp(-k2 * time))) * DMTA - k_M23 * M23 #> d_M27/dt = + f_DMTA_to_M27 * ((k1 * g * exp(-k1 * time) + k2 * (1 - g) #> * exp(-k2 * time)) / (g * exp(-k1 * time) + (1 - g) * #> exp(-k2 * time))) * DMTA - k_M27 * M27 + k_M31 * M31 #> d_M31/dt = + f_DMTA_to_M31 * ((k1 * g * exp(-k1 * time) + k2 * (1 - g) #> * exp(-k2 * time)) / (g * exp(-k1 * time) + (1 - g) * #> exp(-k2 * time))) * DMTA - k_M31 * M31 #> #> Data: #> 568 observations of 4 variable(s) grouped in 6 datasets #> #> Degradation model predictions using RxODE #> #> Fitted in 237.547 s #> #> Variance model: Two-component variance function #> #> Mean of starting values for individual parameters: #> DMTA_0 log_k_M23 log_k_M27 log_k_M31 f_DMTA_ilr_1 f_DMTA_ilr_2 #> 98.7698 -3.9216 -4.3377 -4.2477 0.1380 0.1393 #> f_DMTA_ilr_3 log_k1 log_k2 g_qlogis #> -1.7571 -2.2341 -3.7763 0.4502 #> #> Mean of starting values for error model parameters: #> sigma_low rsd_high #> 0.69793 0.02577 #> #> Fixed degradation parameter values: #> None #> #> Results: #> #> Likelihood calculated by focei #> AIC BIC logLik #> 1936 2031 -945.9 #> #> Optimised parameters: #> est. lower upper #> DMTA_0 98.7698 98.7356 98.8039 #> log_k_M23 -3.9216 -3.9235 -3.9197 #> log_k_M27 -4.3377 -4.3398 -4.3357 #> log_k_M31 -4.2477 -4.2497 -4.2457 #> log_k1 -2.2341 -2.2353 -2.2329 #> log_k2 -3.7763 -3.7781 -3.7744 #> g_qlogis 0.4502 0.4496 0.4507 #> f_DMTA_tffm0_1_qlogis -2.0924 -2.0936 -2.0912 #> f_DMTA_tffm0_2_qlogis -2.1806 -2.1818 -2.1794 #> f_DMTA_tffm0_3_qlogis -2.1427 -2.1439 -2.1415 #> #> Correlation: #> DMTA_0 l__M23 l__M27 l__M31 log_k1 log_k2 g_qlgs #> log_k_M23 0 #> log_k_M27 0 0 #> log_k_M31 0 0 0 #> log_k1 0 0 0 0 #> log_k2 0 0 0 0 0 #> g_qlogis 0 0 0 0 0 0 #> f_DMTA_tffm0_1_qlogis 0 0 0 0 0 0 0 #> f_DMTA_tffm0_2_qlogis 0 0 0 0 0 0 0 #> f_DMTA_tffm0_3_qlogis 0 0 0 0 0 0 0 #> f_DMTA_0_1 f_DMTA_0_2 #> log_k_M23 #> log_k_M27 #> log_k_M31 #> log_k1 #> log_k2 #> g_qlogis #> f_DMTA_tffm0_1_qlogis #> f_DMTA_tffm0_2_qlogis 0 #> f_DMTA_tffm0_3_qlogis 0 0 #> #> Random effects (omega): #> eta.DMTA_0 eta.log_k_M23 eta.log_k_M27 eta.log_k_M31 #> eta.DMTA_0 2.352 0.0000 0.0000 0.0000 #> eta.log_k_M23 0.000 0.5493 0.0000 0.0000 #> eta.log_k_M27 0.000 0.0000 0.8645 0.0000 #> eta.log_k_M31 0.000 0.0000 0.0000 0.7503 #> eta.log_k1 0.000 0.0000 0.0000 0.0000 #> eta.log_k2 0.000 0.0000 0.0000 0.0000 #> eta.g_qlogis 0.000 0.0000 0.0000 0.0000 #> eta.f_DMTA_tffm0_1_qlogis 0.000 0.0000 0.0000 0.0000 #> eta.f_DMTA_tffm0_2_qlogis 0.000 0.0000 0.0000 0.0000 #> eta.f_DMTA_tffm0_3_qlogis 0.000 0.0000 0.0000 0.0000 #> eta.log_k1 eta.log_k2 eta.g_qlogis #> eta.DMTA_0 0.000 0.000 0.000 #> eta.log_k_M23 0.000 0.000 0.000 #> eta.log_k_M27 0.000 0.000 0.000 #> eta.log_k_M31 0.000 0.000 0.000 #> eta.log_k1 0.903 0.000 0.000 #> eta.log_k2 0.000 1.577 0.000 #> eta.g_qlogis 0.000 0.000 3.085 #> eta.f_DMTA_tffm0_1_qlogis 0.000 0.000 0.000 #> eta.f_DMTA_tffm0_2_qlogis 0.000 0.000 0.000 #> eta.f_DMTA_tffm0_3_qlogis 0.000 0.000 0.000 #> eta.f_DMTA_tffm0_1_qlogis eta.f_DMTA_tffm0_2_qlogis #> eta.DMTA_0 0.0 0.0 #> eta.log_k_M23 0.0 0.0 #> eta.log_k_M27 0.0 0.0 #> eta.log_k_M31 0.0 0.0 #> eta.log_k1 0.0 0.0 #> eta.log_k2 0.0 0.0 #> eta.g_qlogis 0.0 0.0 #> eta.f_DMTA_tffm0_1_qlogis 0.3 0.0 #> eta.f_DMTA_tffm0_2_qlogis 0.0 0.3 #> eta.f_DMTA_tffm0_3_qlogis 0.0 0.0 #> eta.f_DMTA_tffm0_3_qlogis #> eta.DMTA_0 0.0 #> eta.log_k_M23 0.0 #> eta.log_k_M27 0.0 #> eta.log_k_M31 0.0 #> eta.log_k1 0.0 #> eta.log_k2 0.0 #> eta.g_qlogis 0.0 #> eta.f_DMTA_tffm0_1_qlogis 0.0 #> eta.f_DMTA_tffm0_2_qlogis 0.0 #> eta.f_DMTA_tffm0_3_qlogis 0.3 #> #> Variance model: #> sigma_low rsd_high #> 0.69793 0.02577 #> #> Backtransformed parameters: #> est. lower upper #> DMTA_0 98.76976 98.73563 98.80390 #> k_M23 0.01981 0.01977 0.01985 #> k_M27 0.01307 0.01304 0.01309 #> k_M31 0.01430 0.01427 0.01433 #> f_DMTA_to_M23 0.10984 NA NA #> f_DMTA_to_M27 0.09036 NA NA #> f_DMTA_to_M31 0.08399 NA NA #> k1 0.10709 0.10696 0.10722 #> k2 0.02291 0.02287 0.02295 #> g 0.61068 0.61055 0.61081 #> #> Resulting formation fractions: #> ff #> DMTA_M23 0.10984 #> DMTA_M27 0.09036 #> DMTA_M31 0.08399 #> DMTA_sink 0.71581 #> #> Estimated disappearance times: #> DT50 DT90 DT50back DT50_k1 DT50_k2 #> DMTA 10.66 59.78 18 6.473 30.26 #> M23 34.99 116.24 NA NA NA #> M27 53.05 176.23 NA NA NA #> M31 48.48 161.05 NA NA NA# Using saemix takes about 18 minutes system.time( f_dmta_saemix <- saem(f_dmta_mkin_tc, test_log_parms = TRUE) )#> Running main SAEM algorithm #> [1] "Tue Jul 27 16:02:34 2021" #> .... #> Minimisation finished #> [1] "Tue Jul 27 16:21:39 2021"#> user system elapsed #> 1213.394 0.087 1213.578# nlmixr with est = "saem" is pretty fast with default iteration numbers, most # of the time (about 2.5 minutes) is spent for calculating the log likelihood at the end # The likelihood calculated for the nlmixr fit is much lower than that found by saemix # Also, the trace plot and the plot of the individual predictions is not # convincing for the parent. It seems we are fitting an overparameterised # model, so the result we get strongly depends on starting parameters and control settings. system.time( f_dmta_nlmixr_saem <- nlmixr(f_dmta_mkin_tc, est = "saem", control = nlmixr::saemControl(print = 500, logLik = TRUE, nmc = 9)) )#>#>#>#>#>#>#> 1: 98.3427 -3.5148 -3.3187 -3.7728 -2.1163 -2.8457 0.9482 -2.8064 -2.7412 -2.8745 2.7912 0.6805 0.8213 0.8055 0.8578 1.4980 2.9309 0.2850 0.2854 0.2850 4.0990 0.3821 3.5349 0.6537 5.4143 0.0002 4.5093 0.1905 #> 500: 97.8277 -4.3506 -4.0318 -4.1520 -3.0553 -3.5843 1.1326 -2.0873 -2.0421 -2.0751 0.2960 1.2515 0.2531 0.3807 0.7928 0.8863 6.5211 0.1433 0.1082 0.3353 0.8960 0.0470 0.7501 0.0475 0.9527 0.0281 0.7321 0.0594#>#>#>#>#>#>#>#>#>#>#>#>#>#> [1] "CMT"#>#>#> user system elapsed #> 818.782 3.808 154.926traceplot(f_dmta_nlmixr_saem$nm)#> Error in traceplot(f_dmta_nlmixr_saem$nm): could not find function "traceplot"#> nlmixr version used for fitting: 2.0.4 #> mkin version used for pre-fitting: 1.1.0 #> R version used for fitting: 4.1.0 #> Date of fit: Tue Jul 27 16:25:23 2021 #> Date of summary: Tue Jul 27 16:25:23 2021 #> #> Equations: #> d_DMTA/dt = - ((k1 * g * exp(-k1 * time) + k2 * (1 - g) * exp(-k2 * #> time)) / (g * exp(-k1 * time) + (1 - g) * exp(-k2 * time))) #> * DMTA #> d_M23/dt = + f_DMTA_to_M23 * ((k1 * g * exp(-k1 * time) + k2 * (1 - g) #> * exp(-k2 * time)) / (g * exp(-k1 * time) + (1 - g) * #> exp(-k2 * time))) * DMTA - k_M23 * M23 #> d_M27/dt = + f_DMTA_to_M27 * ((k1 * g * exp(-k1 * time) + k2 * (1 - g) #> * exp(-k2 * time)) / (g * exp(-k1 * time) + (1 - g) * #> exp(-k2 * time))) * DMTA - k_M27 * M27 + k_M31 * M31 #> d_M31/dt = + f_DMTA_to_M31 * ((k1 * g * exp(-k1 * time) + k2 * (1 - g) #> * exp(-k2 * time)) / (g * exp(-k1 * time) + (1 - g) * #> exp(-k2 * time))) * DMTA - k_M31 * M31 #> #> Data: #> 568 observations of 4 variable(s) grouped in 6 datasets #> #> Degradation model predictions using RxODE #> #> Fitted in 154.632 s #> #> Variance model: Two-component variance function #> #> Mean of starting values for individual parameters: #> DMTA_0 log_k_M23 log_k_M27 log_k_M31 f_DMTA_ilr_1 f_DMTA_ilr_2 #> 98.7698 -3.9216 -4.3377 -4.2477 0.1380 0.1393 #> f_DMTA_ilr_3 log_k1 log_k2 g_qlogis #> -1.7571 -2.2341 -3.7763 0.4502 #> #> Mean of starting values for error model parameters: #> sigma_low_DMTA rsd_high_DMTA sigma_low_M23 rsd_high_M23 sigma_low_M27 #> 0.69793 0.02577 0.69793 0.02577 0.69793 #> rsd_high_M27 sigma_low_M31 rsd_high_M31 #> 0.02577 0.69793 0.02577 #> #> Fixed degradation parameter values: #> None #> #> Results: #> #> Likelihood calculated by focei #> AIC BIC logLik #> 2036 2157 -989.8 #> #> Optimised parameters: #> est. lower upper #> DMTA_0 97.828 96.121 99.535 #> log_k_M23 -4.351 -5.300 -3.401 #> log_k_M27 -4.032 -4.470 -3.594 #> log_k_M31 -4.152 -4.689 -3.615 #> log_k1 -3.055 -3.785 -2.325 #> log_k2 -3.584 -4.517 -2.651 #> g_qlogis 1.133 -2.165 4.430 #> f_DMTA_tffm0_1_qlogis -2.087 -2.407 -1.768 #> f_DMTA_tffm0_2_qlogis -2.042 -2.336 -1.748 #> f_DMTA_tffm0_3_qlogis -2.075 -2.557 -1.593 #> #> Correlation: #> DMTA_0 l__M23 l__M27 l__M31 log_k1 log_k2 g_qlgs #> log_k_M23 -0.031 #> log_k_M27 -0.050 0.004 #> log_k_M31 -0.032 0.003 0.078 #> log_k1 0.014 -0.002 -0.002 -0.001 #> log_k2 0.059 0.006 -0.001 0.002 -0.037 #> g_qlogis -0.077 0.005 0.009 0.004 0.035 -0.201 #> f_DMTA_tffm0_1_qlogis -0.104 0.066 0.009 0.006 0.000 -0.011 0.014 #> f_DMTA_tffm0_2_qlogis -0.120 0.013 0.081 -0.033 -0.002 -0.013 0.017 #> f_DMTA_tffm0_3_qlogis -0.086 0.010 0.060 0.078 -0.002 -0.005 0.010 #> f_DMTA_0_1 f_DMTA_0_2 #> log_k_M23 #> log_k_M27 #> log_k_M31 #> log_k1 #> log_k2 #> g_qlogis #> f_DMTA_tffm0_1_qlogis #> f_DMTA_tffm0_2_qlogis 0.026 #> f_DMTA_tffm0_3_qlogis 0.019 0.002 #> #> Random effects (omega): #> eta.DMTA_0 eta.log_k_M23 eta.log_k_M27 eta.log_k_M31 #> eta.DMTA_0 0.296 0.000 0.0000 0.0000 #> eta.log_k_M23 0.000 1.252 0.0000 0.0000 #> eta.log_k_M27 0.000 0.000 0.2531 0.0000 #> eta.log_k_M31 0.000 0.000 0.0000 0.3807 #> eta.log_k1 0.000 0.000 0.0000 0.0000 #> eta.log_k2 0.000 0.000 0.0000 0.0000 #> eta.g_qlogis 0.000 0.000 0.0000 0.0000 #> eta.f_DMTA_tffm0_1_qlogis 0.000 0.000 0.0000 0.0000 #> eta.f_DMTA_tffm0_2_qlogis 0.000 0.000 0.0000 0.0000 #> eta.f_DMTA_tffm0_3_qlogis 0.000 0.000 0.0000 0.0000 #> eta.log_k1 eta.log_k2 eta.g_qlogis #> eta.DMTA_0 0.0000 0.0000 0.000 #> eta.log_k_M23 0.0000 0.0000 0.000 #> eta.log_k_M27 0.0000 0.0000 0.000 #> eta.log_k_M31 0.0000 0.0000 0.000 #> eta.log_k1 0.7928 0.0000 0.000 #> eta.log_k2 0.0000 0.8863 0.000 #> eta.g_qlogis 0.0000 0.0000 6.521 #> eta.f_DMTA_tffm0_1_qlogis 0.0000 0.0000 0.000 #> eta.f_DMTA_tffm0_2_qlogis 0.0000 0.0000 0.000 #> eta.f_DMTA_tffm0_3_qlogis 0.0000 0.0000 0.000 #> eta.f_DMTA_tffm0_1_qlogis eta.f_DMTA_tffm0_2_qlogis #> eta.DMTA_0 0.0000 0.0000 #> eta.log_k_M23 0.0000 0.0000 #> eta.log_k_M27 0.0000 0.0000 #> eta.log_k_M31 0.0000 0.0000 #> eta.log_k1 0.0000 0.0000 #> eta.log_k2 0.0000 0.0000 #> eta.g_qlogis 0.0000 0.0000 #> eta.f_DMTA_tffm0_1_qlogis 0.1433 0.0000 #> eta.f_DMTA_tffm0_2_qlogis 0.0000 0.1082 #> eta.f_DMTA_tffm0_3_qlogis 0.0000 0.0000 #> eta.f_DMTA_tffm0_3_qlogis #> eta.DMTA_0 0.0000 #> eta.log_k_M23 0.0000 #> eta.log_k_M27 0.0000 #> eta.log_k_M31 0.0000 #> eta.log_k1 0.0000 #> eta.log_k2 0.0000 #> eta.g_qlogis 0.0000 #> eta.f_DMTA_tffm0_1_qlogis 0.0000 #> eta.f_DMTA_tffm0_2_qlogis 0.0000 #> eta.f_DMTA_tffm0_3_qlogis 0.3353 #> #> Variance model: #> sigma_low_DMTA rsd_high_DMTA sigma_low_M23 rsd_high_M23 sigma_low_M27 #> 0.89603 0.04704 0.75015 0.04753 0.95265 #> rsd_high_M27 sigma_low_M31 rsd_high_M31 #> 0.02810 0.73212 0.05942 #> #> Backtransformed parameters: #> est. lower upper #> DMTA_0 97.82774 96.120503 99.53498 #> k_M23 0.01290 0.004991 0.03334 #> k_M27 0.01774 0.011451 0.02749 #> k_M31 0.01573 0.009195 0.02692 #> f_DMTA_to_M23 0.11033 NA NA #> f_DMTA_to_M27 0.10218 NA NA #> f_DMTA_to_M31 0.08784 NA NA #> k1 0.04711 0.022707 0.09773 #> k2 0.02775 0.010918 0.07056 #> g 0.75632 0.102960 0.98823 #> #> Resulting formation fractions: #> ff #> DMTA_M23 0.11033 #> DMTA_M27 0.10218 #> DMTA_M31 0.08784 #> DMTA_sink 0.69965 #> #> Estimated disappearance times: #> DT50 DT90 DT50back DT50_k1 DT50_k2 #> DMTA 16.59 57.44 17.29 14.71 24.97 #> M23 53.74 178.51 NA NA NA #> M27 39.07 129.78 NA NA NA #> M31 44.06 146.36 NA NA NA# }